Un aspecto importante de Aprendizaje automático es la evaluación del modelo. Necesita tener algún mecanismo para evaluar su modelo. Aquí es donde estas métricas de rendimiento entran en escena: nos dan una idea de lo bueno que es un modelo. Si está familiarizado con algunos de los conceptos básicos de Aprendizaje automático entonces debes haberte encontrado con algunas de estas métricas, como exactitud, precisión, recuperación, auc-roc, etc., que generalmente se utilizan para tareas de clasificación. En este artículo, exploraremos en profundidad una de esas métricas, que es la curva AUC-ROC.
Tabla de contenidos
- ¿Qué es la curva AUC-ROC?
- Términos clave utilizados en las curvas AUC y ROC
- Relación entre Sensibilidad, Especificidad, FPR y Umbral.
- ¿Cómo funciona AUC-ROC?
- ¿Cuándo deberíamos utilizar la métrica de evaluación AUC-ROC?
- Especular el rendimiento del modelo.
- Comprender la curva AUC-ROC
- Implementación utilizando dos modelos diferentes.
- ¿Cómo utilizar ROC-AUC para un modelo multiclase?
- Preguntas frecuentes sobre la curva AUC ROC en el aprendizaje automático
¿Qué es la curva AUC-ROC?
La curva AUC-ROC, o área bajo la curva característica operativa del receptor, es una representación gráfica del rendimiento de un modelo de clasificación binaria en varios umbrales de clasificación. Se utiliza habitualmente en el aprendizaje automático para evaluar la capacidad de un modelo para distinguir entre dos clases, normalmente la clase positiva (p. ej., presencia de una enfermedad) y la clase negativa (p. ej., ausencia de una enfermedad).
Primero comprendamos el significado de los dos términos. República de China y AUC .
- República de China : Características de funcionamiento del receptor
- AUC : Área bajo curva
Curva de características operativas del receptor (ROC)
ROC significa Características operativas del receptor y la curva ROC es la representación gráfica de la efectividad del modelo de clasificación binaria. Traza la tasa de verdaderos positivos (TPR) frente a la tasa de falsos positivos (FPR) en diferentes umbrales de clasificación.
Área bajo curva (AUC) Curva:
AUC significa Área bajo la curva y la curva AUC representa el área bajo la curva ROC. Mide el rendimiento general del modelo de clasificación binaria. Como tanto TPR como FPR oscilan entre 0 y 1, el área siempre estará entre 0 y 1, y un valor mayor de AUC denota un mejor rendimiento del modelo. Nuestro principal objetivo es maximizar esta área para tener el TPR más alto y el FPR más bajo en el umbral dado. El AUC mide la probabilidad de que el modelo asigne a una instancia positiva elegida al azar una probabilidad predicha más alta en comparación con una instancia negativa elegida al azar.
Representa el probabilidad con lo cual nuestro modelo puede distinguir entre las dos clases presentes en nuestro objetivo.
Métrica de evaluación de clasificación ROC-AUC
Términos clave utilizados en las curvas AUC y ROC
1. EPC y FPR
Esta es la definición más común que habría encontrado cuando buscó en Google AUC-ROC. Básicamente, la curva ROC es un gráfico que muestra el rendimiento de un modelo de clasificación en todos los umbrales posibles (el umbral es un valor particular más allá del cual se dice que un punto pertenece a una clase particular). La curva se traza entre dos parámetros.
- TPR – Tasa de verdaderos positivos
- FPR – Tasa de falsos positivos
Antes de comprender, TPR y FPR veamos rápidamente el matriz de confusión .
eres empalme
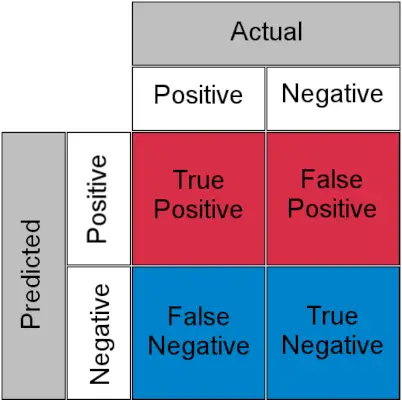
Matriz de confusión para una tarea de clasificación
- Verdadero positivo : Positivo real y previsto como positivo
- Verdadero Negativo : Negativo real y previsto como negativo
- Falso positivo (error tipo I) : Negativo real pero previsto como positivo
- Falso negativo (error tipo II) : Positivo real pero previsto como negativo
En términos simples, puedes llamar Falso Positivo a falsa alarma y falso negativo a extrañar . Ahora veamos qué son TPR y FPR.
2. Sensibilidad / Tasa de verdaderos positivos / Recuerdo
Básicamente, TPR/Recall/Sensitivity es la proporción de ejemplos positivos que se identifican correctamente. Representa la capacidad del modelo para identificar correctamente instancias positivas y se calcula de la siguiente manera:

Sensibilidad/Recuerdo/TPR mide la proporción de casos positivos reales que el modelo identifica correctamente como positivos.
3. Tasa de falsos positivos
FPR es la proporción de ejemplos negativos que están clasificados incorrectamente.

4. Especificidad
La especificidad mide la proporción de casos negativos reales que el modelo identifica correctamente como negativos. Representa la capacidad del modelo para identificar correctamente instancias negativas.

Y como se dijo anteriormente, ROC no es más que la gráfica entre TPR y FPR en todos los umbrales posibles y AUC es el área completa debajo de esta curva ROC.
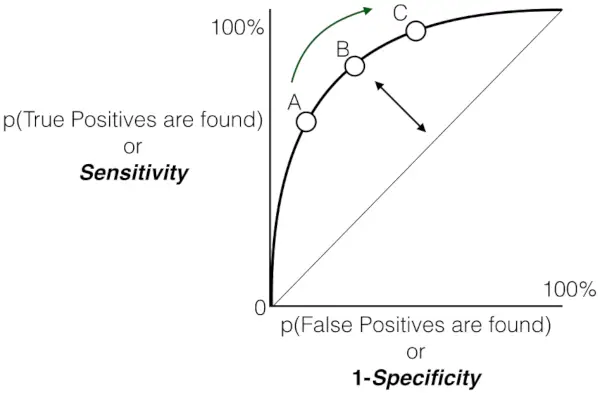
Gráfico de sensibilidad versus tasa de falsos positivos
Relación entre sensibilidad, especificidad, FPR y umbral .
Sensibilidad y especificidad:
- Relación inversa: la sensibilidad y la especificidad tienen una relación inversa. Cuando uno aumenta, el otro tiende a disminuir. Esto refleja el equilibrio inherente entre tasas verdaderamente positivas y verdaderas negativas.
- Sintonización mediante umbral: Al ajustar el valor umbral, podemos controlar el equilibrio entre sensibilidad y especificidad. Los umbrales más bajos conducen a una mayor sensibilidad (más verdaderos positivos) a expensas de la especificidad (más falsos positivos). Por el contrario, elevar el umbral aumenta la especificidad (menos falsos positivos) pero sacrifica la sensibilidad (más falsos negativos).
Umbral y tasa de falsos positivos (FPR):
- FPR y conexión de especificidad: La tasa de falsos positivos (FPR) es simplemente el complemento de la especificidad (FPR = 1 – especificidad). Esto significa la relación directa entre ellos: una mayor especificidad se traduce en un menor FPR, y viceversa.
- Cambios en el FPR con el TPR: De manera similar, como observó, la tasa de verdaderos positivos (TPR) y la FPR también están vinculadas. Un aumento en la TPR (más positivos verdaderos) generalmente conduce a un aumento en la FPR (más falsos positivos). Por el contrario, una caída en la TPR (menos positivos verdaderos) da como resultado una disminución en la FPR (menos falsos positivos)
¿Cómo funciona AUC-ROC?
Analizamos la interpretación geométrica, pero supongo que todavía no es suficiente para desarrollar la intuición detrás de lo que realmente significa 0,75 AUC. Ahora miremos AUC-ROC desde un punto de vista probabilístico. Primero hablemos de lo que hacen las AUC y luego desarrollaremos nuestra comprensión sobre esto.
El AUC mide qué tan bien un modelo es capaz de distinguir entre clases.
Un AUC de 0,75 en realidad significaría que, digamos que tomamos dos puntos de datos que pertenecen a clases separadas, entonces hay un 75% de posibilidades de que el modelo pueda segregarlos o clasificarlos correctamente, es decir, el punto positivo tiene una probabilidad de predicción más alta que el negativo. clase. (asumir una probabilidad de predicción más alta significa que el punto idealmente pertenecería a la clase positiva). Aquí tenéis un pequeño ejemplo para que las cosas queden más claras.
Índice | Clase | Probabilidad |
|---|---|---|
P1 | 1 | 0.95 |
P2 | 1 | 0.90 |
P3 | 0 | 0.85 |
P4 | 0 | 0.81 |
P5 | 1 | 0.78 |
P6 | 0 | 0.70 |
Aquí tenemos 6 puntos donde P1, P2 y P5 pertenecen a la clase 1 y P3, P4 y P6 pertenecen a la clase 0 y tenemos las probabilidades predichas correspondientes en la columna Probabilidad, como dijimos si tomamos dos puntos que pertenecen a puntos separados. clases, entonces ¿cuál es la probabilidad de que la clasificación del modelo las ordene correctamente?
Tomaremos todos los pares posibles de modo que un punto pertenezca a la clase 1 y el otro pertenezca a la clase 0, tendremos un total de 9 pares de este tipo a continuación, son todos estos 9 pares posibles.
Par | es correcto |
|---|---|
(P1,P3) | Sí |
(P1,P4) | Sí |
(P1,P6) | Sí |
(P2,P3) | Sí |
(P2,P4) | Sí |
(P2,P6) | Sí |
(P3,P5) | No |
(P4,P5) | No |
(P5,P6) | Sí |
Aquí la columna Correcto indica si el par mencionado está ordenado correctamente según la probabilidad prevista, es decir, el punto de clase 1 tiene una probabilidad mayor que el punto de clase 0, en 7 de estos 9 pares posibles, la clase 1 se clasifica por encima de la clase 0, o Podemos decir que hay un 77% de posibilidades de que si elige un par de puntos que pertenecen a clases separadas, el modelo pueda distinguirlos correctamente. Ahora, creo que es posible que tengas un poco de intuición detrás de este número AUC, solo para aclarar más dudas, validémoslo usando Scikit aprende la implementación AUC-ROC.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Producción:
AUC for our sample data is 0.778>
¿Cuándo deberíamos utilizar la métrica de evaluación AUC-ROC?
Hay algunas áreas donde el uso de ROC-AUC puede no ser ideal. En los casos en que el conjunto de datos esté muy desequilibrado, la curva ROC puede dar una evaluación demasiado optimista del rendimiento del modelo . Este sesgo de optimismo surge porque la tasa de falsos positivos (FPR) de la curva ROC puede volverse muy pequeña cuando el número de negativos reales es grande.
Mirando la fórmula FPR,

observamos ,
- La clase Negativa es mayoritaria, el denominador de FPR está dominado por Verdaderos Negativos, por lo que FPR se vuelve menos sensible a los cambios en las predicciones relacionadas con la clase minoritaria (clase positiva).
- Las curvas ROC pueden ser apropiadas cuando el costo de los falsos positivos y los falsos negativos está equilibrado y el conjunto de datos no está muy desequilibrado.
En esos casos, Curvas de recuperación de precisión se puede utilizar que proporciona una métrica de evaluación alternativa que es más adecuada para conjuntos de datos desequilibrados, centrándose en el rendimiento del clasificador con respecto a la clase positiva (minoría).
Especular el rendimiento del modelo.
- Un AUC alto (cercano a 1) indica un excelente poder discriminativo. Esto significa que el modelo es eficaz para distinguir entre las dos clases y sus predicciones son fiables.
- Un AUC bajo (cerca de 0) sugiere un rendimiento deficiente. En este caso, el modelo tiene dificultades para diferenciar entre las clases positivas y negativas, y sus predicciones pueden no ser confiables.
- Un AUC de alrededor de 0,5 implica que el modelo esencialmente hace conjeturas aleatorias. No muestra ninguna capacidad para separar las clases, lo que indica que el modelo no está aprendiendo ningún patrón significativo de los datos.
Comprender la curva AUC-ROC
En una curva ROC, el eje x normalmente representa la tasa de falsos positivos (FPR) y el eje y representa la tasa de verdaderos positivos (TPR), también conocida como sensibilidad o recuperación. Por lo tanto, un valor más alto del eje x (hacia la derecha) en la curva ROC indica una tasa de falsos positivos más alta, y un valor más alto del eje y (hacia la parte superior) indica una tasa de verdaderos positivos más alta. La curva ROC es una representación gráfica. representación de la compensación entre la tasa de verdaderos positivos y la tasa de falsos positivos en varios umbrales. Muestra el rendimiento de un modelo de clasificación en diferentes umbrales de clasificación. El AUC (área bajo la curva) es una medida resumida del rendimiento de la curva ROC. La elección del umbral depende de los requisitos específicos del problema que intenta resolver y del equilibrio entre falsos positivos y falsos negativos, es decir. aceptable en su contexto.
- Si desea priorizar la reducción de falsos positivos (minimizando las posibilidades de etiquetar algo como positivo cuando no lo es), puede elegir un umbral que dé como resultado una tasa de falsos positivos más baja.
- Si desea priorizar el aumento de los verdaderos positivos (capturar tantos positivos reales como sea posible), puede elegir un umbral que dé como resultado una tasa de verdaderos positivos más alta.
Consideremos un ejemplo para ilustrar cómo se generan las curvas ROC para diferentes umbrales y cómo un umbral particular corresponde a una matriz de confusión. Supongamos que tenemos un problema de clasificación binaria con un modelo que predice si un correo electrónico es spam (positivo) o no spam (negativo).
Consideremos los datos hipotéticos,
Etiquetas verdaderas: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Probabilidades previstas: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Caso 1: Umbral = 0,5
Etiquetas verdaderas | Probabilidades previstas | Etiquetas previstas |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
Matriz de confusión basada en las predicciones anteriores
| Predicción = 0 | Predicción = 1 |
|---|---|---|
Real = 0 | TP=4 | FN=1 |
Real = 1 | PF=0 | TN=5 |
Respectivamente,
- Tasa de verdaderos positivos (TPR) :
La proporción de positivos reales identificados correctamente por el clasificador es

- Tasa de falsos positivos (FPR) :
Proporción de negativos reales clasificados incorrectamente como positivos



Entonces, en el umbral de 0,5:
- Tasa de verdaderos positivos (sensibilidad): 0,8
- Tasa de falsos positivos: 0
La interpretación es que el modelo, en este umbral, identifica correctamente el 80% de los positivos reales (TPR) pero clasifica incorrectamente el 0% de los negativos reales como positivos (FPR).
En consecuencia, para diferentes umbrales obtendremos,
Caso 2: Umbral = 0,7
Etiquetas verdaderas | Probabilidades previstas | Etiquetas previstas |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 0 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 0 |
Matriz de confusión basada en las predicciones anteriores
| Predicción = 0 | Predicción = 1 |
|---|---|---|
Real = 0 | TP=5 | FN=0 |
Real = 1 | PF=2 | TN=3 |
Respectivamente,
- Tasa de verdaderos positivos (TPR) :
La proporción de positivos reales identificados correctamente por el clasificador es

- Tasa de falsos positivos (FPR) :
Proporción de negativos reales clasificados incorrectamente como positivos



Caso 3: Umbral = 0,4
Etiquetas verdaderas | Probabilidades previstas | Etiquetas previstas |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
Matriz de confusión basada en las predicciones anteriores
| Predicción = 0 | Predicción = 1 |
|---|---|---|
Real = 0 | TP=4 | FN=1 |
Real = 1 | PF=0 | TN=5 |
Respectivamente,
- Tasa de verdaderos positivos (TPR) :
La proporción de positivos reales identificados correctamente por el clasificador es
- Tasa de falsos positivos (FPR) :
Proporción de negativos reales clasificados incorrectamente como positivos
Caso 4: Umbral = 0,2
Etiquetas verdaderas | Probabilidades previstas | Etiquetas previstas |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 1 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 1 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
Matriz de confusión basada en las predicciones anteriores
| Predicción = 0 | Predicción = 1 |
|---|---|---|
Real = 0 | TP=2 | FN=3 |
Real = 1 | PF=0 | TN=5 |
Respectivamente,
- Tasa de verdaderos positivos (TPR) :
La proporción de positivos reales identificados correctamente por el clasificador es

- Tasa de falsos positivos (FPR) :
Proporción de negativos reales clasificados incorrectamente como positivos

Caso 5: Umbral = 0,85
Etiquetas verdaderas | Probabilidades previstas | Etiquetas previstas |
|---|---|---|
| 1 | 0.8 | 0 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 0 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 0 |
| 0 | 0.55 | 0 |
Matriz de confusión basada en las predicciones anteriores
| Predicción = 0 | Predicción = 1 |
|---|---|---|
Real = 0 | TP=5 | FN=0 |
Real = 1 | PF=4 | TN=1 |
Respectivamente,
- Tasa de verdaderos positivos (TPR) :
La proporción de positivos reales identificados correctamente por el clasificador es
- Tasa de falsos positivos (FPR) :
Proporción de negativos reales clasificados incorrectamente como positivos


Con base en el resultado anterior, trazaremos la curva ROC
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Producción:
Del gráfico se deduce que:
- La línea discontinua gris representa el peor de los casos, donde las predicciones del modelo, es decir, TPR son FPR, son las mismas. Esta línea diagonal se considera el peor de los casos, lo que indica la misma probabilidad de que se produzcan falsos positivos y falsos negativos.
- A medida que los puntos se desvían de la línea de conjetura aleatoria hacia la esquina superior izquierda, el rendimiento del modelo mejora.
- El área bajo la curva (AUC) es una medida cuantitativa de la capacidad discriminativa del modelo. Un valor de AUC más alto, más cercano a 1,0, indica un rendimiento superior. El mejor valor de AUC posible es 1,0, correspondiente a un modelo que alcanza el 100% de sensibilidad y el 100% de especificidad.
En total, la curva de característica operativa del receptor (ROC) sirve como una representación gráfica del equilibrio entre la tasa de verdaderos positivos (sensibilidad) y la tasa de falsos positivos de un modelo de clasificación binaria en varios umbrales de decisión. A medida que la curva asciende con gracia hacia la esquina superior izquierda, indica la encomiable capacidad del modelo para discriminar entre casos positivos y negativos en una variedad de umbrales de confianza. Esta trayectoria ascendente indica un rendimiento mejorado, con una mayor sensibilidad lograda y al mismo tiempo minimizando los falsos positivos. Los umbrales anotados, denominados A, B, C, D y E, ofrecen información valiosa sobre el comportamiento dinámico del modelo en diferentes niveles de confianza.
Implementación utilizando dos modelos diferentes.
Instalación de bibliotecas
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Para entrenar a los Bosque aleatorio y Regresión logística modelos y para presentar sus curvas ROC con puntuaciones AUC, el algoritmo crea datos de clasificación binaria artificiales.
Generar datos y dividir datos
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Utilizando una proporción de división de 80-20, el algoritmo crea datos de clasificación binaria artificial con 20 características, los divide en conjuntos de entrenamiento y prueba y asigna una semilla aleatoria para garantizar la reproducibilidad.
Entrenando los diferentes modelos.
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Utilizando una semilla aleatoria fija para garantizar la repetibilidad, el método inicializa y entrena un modelo de regresión logística en el conjunto de entrenamiento. De manera similar, utiliza los datos de entrenamiento y la misma semilla aleatoria para inicializar y entrenar un modelo de Random Forest con 100 árboles.
Predicciones
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Usando los datos de prueba y un capacitado Regresión logística modelo, el código predice la probabilidad de la clase positiva. De manera similar, utilizando los datos de prueba, utiliza el modelo Random Forest entrenado para producir probabilidades proyectadas para la clase positiva.
Creando un marco de datos
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Utilizando los datos de prueba, el código crea un DataFrame llamado test_df con columnas etiquetadas como True, Logistic y RandomForest, agregando etiquetas verdaderas y probabilidades predichas de los modelos Random Forest y Logistic Regression.
Trazar la curva ROC para los modelos.
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Producción:
la cadena java está vacía

El código genera un gráfico con figuras de 8 por 6 pulgadas. Calcula la curva AUC y ROC para cada modelo (bosque aleatorio y regresión logística) y luego traza la curva ROC. El curva ROC para adivinanzas aleatorias también se representa con una línea discontinua roja, y se establecen etiquetas, un título y una leyenda para la visualización.
¿Cómo utilizar ROC-AUC para un modelo multiclase?
Para una configuración de varias clases, simplemente podemos usar la metodología uno versus todos y tendrá una curva ROC para cada clase. Digamos que tiene cuatro clases A, B, C y D, entonces habría curvas ROC y los valores AUC correspondientes para las cuatro clases, es decir, una vez que A sería una clase y B, C y D combinados serían las otras clases. De manera similar, B es una clase y A, C y D se combinan como otras clases, etc.
Los pasos generales para utilizar AUC-ROC en el contexto de un modelo de clasificación multiclase son:
Metodología uno contra todos:
- Para cada clase en su problema multiclase, trátela como la clase positiva mientras combina todas las demás clases en la clase negativa.
- Entrene el clasificador binario para cada clase frente al resto de clases.
Calcule AUC-ROC para cada clase:
- Aquí trazamos la curva ROC para la clase dada frente al resto.
- Traza las curvas ROC para cada clase en el mismo gráfico. Cada curva representa el desempeño de discriminación del modelo para una clase específica.
- Examine los puntajes AUC para cada clase. Una puntuación AUC más alta indica una mejor discriminación para esa clase en particular.
Implementación de AUC-ROC en clasificación multiclase
Importación de bibliotecas
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
El programa crea datos artificiales multiclase, los divide en conjuntos de entrenamiento y prueba, y luego usa el Clasificador uno versus resto Técnica para entrenar clasificadores tanto para bosque aleatorio como para regresión logística. Por último, traza las curvas ROC multiclase de los dos modelos para demostrar qué tan bien discriminan entre varias clases.
Generando datos y dividiendo
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Tres clases y veinte características conforman los datos sintéticos multiclase producidos por el código. Después de la binarización de etiquetas, los datos se dividen en conjuntos de entrenamiento y prueba en una proporción de 80-20.
Modelos de entrenamiento
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
El programa entrena dos modelos multiclase: un modelo de Bosque Aleatorio con 100 estimadores y un modelo de Regresión Logística con el Enfoque uno contra el resto . Con el conjunto de datos de entrenamiento, se ajustan ambos modelos.
Trazar la curva AUC-ROC
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Producción:

Las curvas ROC y las puntuaciones AUC de los modelos de bosque aleatorio y regresión logística se calculan mediante el código para cada clase. Luego se trazan las curvas ROC multiclase, que muestran el desempeño de discriminación de cada clase y presentan una línea que representa conjeturas aleatorias. El gráfico resultante ofrece una evaluación gráfica del rendimiento de clasificación de los modelos.
Conclusión
En el aprendizaje automático, el rendimiento de los modelos de clasificación binaria se evalúa utilizando una métrica crucial llamada Área bajo la característica operativa del receptor (AUC-ROC). A través de varios umbrales de decisión, muestra cómo se compensan la sensibilidad y la especificidad. Un modelo con una puntuación AUC más alta suele mostrar una mayor discriminación entre instancias positivas y negativas. Mientras que 0,5 denota probabilidad, 1 representa un desempeño impecable. La optimización y selección del modelo se ven favorecidas por la información útil que ofrece la curva AUC-ROC sobre la capacidad de un modelo para discriminar entre clases. Cuando se trabaja con conjuntos de datos desequilibrados o aplicaciones donde los falsos positivos y los falsos negativos tienen costos diferentes, es particularmente útil como medida integral.
Preguntas frecuentes sobre la curva AUC ROC en el aprendizaje automático
1. ¿Qué es la curva AUC-ROC?
Para varios umbrales de clasificación, el equilibrio entre la tasa de verdaderos positivos (sensibilidad) y la tasa de falsos positivos (especificidad) se representa gráficamente mediante la curva AUC-ROC.
2. ¿Cómo es una curva AUC-ROC perfecta?
Un área de 1 en una curva AUC-ROC ideal significaría que el modelo logra una sensibilidad y especificidad óptimas en todos los umbrales.
3. ¿Qué significa un valor AUC de 0,5?
Un AUC de 0,5 indica que el rendimiento del modelo es comparable al del azar. Sugiere una falta de capacidad de discriminación.
4. ¿Se puede utilizar AUC-ROC para la clasificación multiclase?
AUC-ROC se aplica con frecuencia a cuestiones relacionadas con la clasificación binaria. Se pueden tener en cuenta variaciones como el AUC macropromedio o micropromedio para la clasificación multiclase.
5. ¿Qué utilidad tiene la curva AUC-ROC en la evaluación de modelos?
La capacidad de un modelo para discriminar entre clases se resume de manera integral en la curva AUC-ROC. Cuando se trabaja con conjuntos de datos desequilibrados, resulta especialmente útil.