Los mapas hash son estructuras de datos indexados. Un mapa hash hace uso de un función hash para calcular un índice con una clave en una matriz de depósitos o ranuras. Su valor se asigna al depósito con el índice correspondiente. La clave es única e inmutable. Piense en un mapa hash como un gabinete que tiene cajones con etiquetas para las cosas guardadas en ellos. Por ejemplo, almacenar información del usuario: considere el correo electrónico como la clave y podremos asignar los valores correspondientes a ese usuario, como el nombre, el apellido, etc., a un depósito.
La función hash es el núcleo de la implementación de un mapa hash. Toma la clave y la traduce al índice de un depósito en la lista de depósitos. El hash ideal debería producir un índice diferente para cada clave. Sin embargo, pueden ocurrir colisiones. Cuando el hash proporciona un índice existente, simplemente podemos usar un depósito para múltiples valores agregando una lista o repitiendo.
En Python, los diccionarios son ejemplos de mapas hash. Veremos la implementación del mapa hash desde cero para aprender cómo construir y personalizar dichas estructuras de datos para optimizar la búsqueda.
El diseño del mapa hash incluirá las siguientes funciones:
- set_val(clave, valor): Inserta un par clave-valor en el mapa hash. Si el valor ya existe en el mapa hash, actualice el valor.
- get_val(clave): Devuelve el valor al que está asignada la clave especificada, o No se encontró ningún registro si esta asignación no contiene ninguna asignación para la clave.
- eliminar_val (clave): Elimina la asignación de la clave específica si el mapa hash contiene la asignación de la clave.
A continuación se muestra la implementación.
Python3
gimp reemplazar color
class> HashTable:> ># Create empty bucket list of given size> >def> __init__(>self>, size):> >self>.size>=> size> >self>.hash_table>=> self>.create_buckets()> >def> create_buckets(>self>):> >return> [[]>for> _>in> range>(>self>.size)]> ># Insert values into hash map> >def> set_val(>self>, key, val):> > ># Get the index from the key> ># using hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be inserted> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key to be inserted,> ># Update the key value> ># Otherwise append the new key-value pair to the bucket> >if> found_key:> >bucket[index]>=> (key, val)> >else>:> >bucket.append((key, val))> ># Return searched value with specific key> >def> get_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key being searched> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key being searched,> ># Return the value found> ># Otherwise indicate there was no record found> >if> found_key:> >return> record_val> >else>:> >return> 'No record found'> ># Remove a value with specific key> >def> delete_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be deleted> >if> record_key>=>=> key:> >found_key>=> True> >break> >if> found_key:> >bucket.pop(index)> >return> ># To print the items of hash map> >def> __str__(>self>):> >return> ''.join(>str>(item)>for> item>in> self>.hash_table)> hash_table>=> HashTable(>50>)> # insert some values> hash_table.set_val(>'[email protected]'>,>'some value'>)> print>(hash_table)> print>()> hash_table.set_val(>'[email protected]'>,>'some other value'>)> print>(hash_table)> print>()> # search/access a record with key> print>(hash_table.get_val(>'[email protected]'>))> print>()> # delete or remove a value> hash_table.delete_val(>'[email protected]'>)> print>(hash_table)> |
>
>
corrimiento al rojo
Producción:
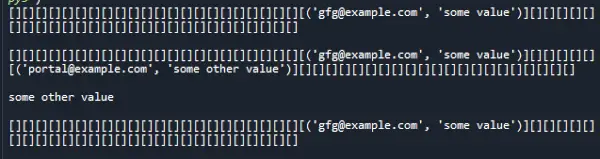
Complejidad del tiempo:
El acceso al índice de memoria requiere un tiempo constante y el hash requiere un tiempo constante. Por lo tanto, la complejidad de búsqueda de un mapa hash también es un tiempo constante, es decir, O (1).
Ventajas de HashMaps
● Acceso rápido a la memoria aleatoria a través de funciones hash
● Puede utilizar valores negativos y no integrales para acceder a los valores.
● Las claves se pueden almacenar en orden, por lo que se pueden iterar fácilmente sobre los mapas.
Desventajas de HashMaps
● Las colisiones pueden causar grandes penalizaciones y pueden hacer que la complejidad del tiempo se vuelva lineal.
● Cuando el número de claves es grande, una única función hash suele provocar colisiones.
Aplicaciones de HashMaps
● Tienen aplicaciones en implementaciones de caché donde las ubicaciones de memoria se asignan a conjuntos pequeños.
● Se utilizan para indexar tuplas en sistemas de gestión de bases de datos.
año mes
● También se utilizan en algoritmos como la coincidencia de patrones de Rabin Karp.