- Redshift es un servicio de almacenamiento de datos a escala de petabytes, rápido y potente, totalmente gestionado en la nube.
- Los clientes pueden usar Redshift por solo
- Redshift es un servicio de almacenamiento de datos a escala de petabytes, rápido y potente, totalmente gestionado en la nube.
- Los clientes pueden usar Redshift por solo $0,25 por hora sin compromisos ni costos iniciales y escalar a un petabyte o más por $1000 por terabyte al año.
OLAP
OLAP es un Sistema de procesamiento de análisis en línea utilizado por el corrimiento al rojo .
Ejemplo de transacción OLAP:
Supongamos que queremos calcular el beneficio neto para EMEA y Pacífico del producto de radio digital. Esto requiere extraer una gran cantidad de registros. Los siguientes son los registros necesarios para calcular una ganancia neta:
- Suma de Radios vendidas en EMEA.
- Sumatoria de Radios vendidas en Pacífico.
- Costo unitario de la radio en cada región.
- Precio de venta de cada radio.
- Precio de venta - costo unitario
Se requieren consultas complejas para recuperar los registros proporcionados anteriormente. Las bases de datos de almacenamiento de datos utilizan diferentes tipos de arquitectura tanto desde la perspectiva de la base de datos como desde la capa de infraestructura.
Configuración de desplazamiento al rojo
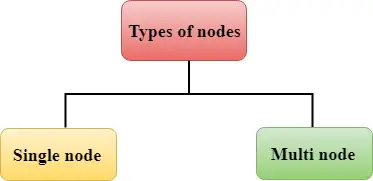
Redshift consta de dos tipos de nodos:
Nodo único Multinodo Nodo único: Un solo nodo almacena hasta 160 GB.
Multinodo: Un nodo múltiple es un nodo que consta de más de un nodo. Es de dos tipos:
Nodo líder
Gestiona las conexiones de los clientes y recibe consultas. Un nodo líder recibe las consultas de las aplicaciones cliente, las analiza y desarrolla los planes de ejecución. Se coordina con la ejecución paralela de estos planes con el nodo de cómputo y combina los resultados intermedios de todos los nodos, y luego devuelve el resultado final a la aplicación cliente.Nodo de cálculo
Un nodo de cálculo ejecuta los planes de ejecución y luego los resultados intermedios se envían al nodo líder para su agregación antes de enviarlos de regreso a la aplicación cliente. Puede tener hasta 128 nodos de cómputo.Entendamos el concepto de nodo líder y nodos de cálculo a través de un ejemplo.
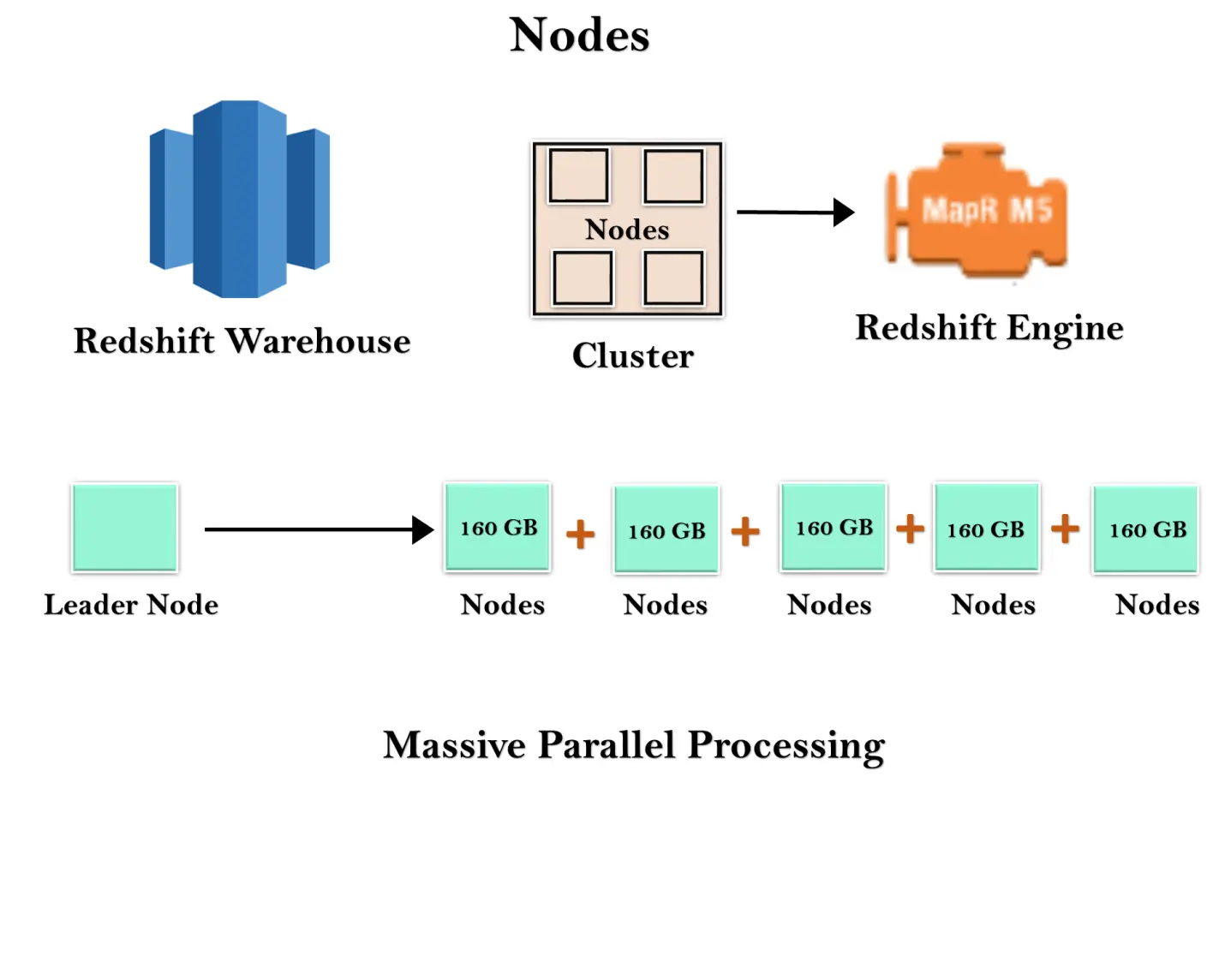
El almacén de Redshift es una colección de recursos informáticos conocidos como nodos, y estos nodos están organizados en un grupo conocido como clúster. Cada clúster se ejecuta en un motor Redshift que contiene una o más bases de datos.
Cuando lanza una instancia de Redshift, comienza con un único nodo de 160 GB de tamaño. Cuando desee crecer, puede agregar nodos adicionales para aprovechar el procesamiento paralelo. Tiene un nodo líder que gestiona los múltiples nodos. El nodo líder maneja la conexión del cliente, así como los nodos de computación. Almacena los datos en nodos informáticos y realiza la consulta.
Por qué Redshift es 10 veces más rápido
El desplazamiento al rojo es 10 veces más rápido por las siguientes razones:
Almacenamiento de datos en columnas
En lugar de almacenar datos como una serie de filas, Amazon Redshift organiza los datos por columnas. Los sistemas basados en filas son ideales para el procesamiento de transacciones, mientras que los sistemas basados en columnas son ideales para el almacenamiento y análisis de datos, donde las consultas a menudo implican agregados realizados en grandes conjuntos de datos. Dado que solo se procesan las columnas involucradas en las consultas y los datos de las columnas se almacenan secuencialmente en un medio de almacenamiento, los sistemas basados en columnas requieren menos E/S, lo que mejora el rendimiento de las consultas.Compresión avanzada
Los almacenes de datos en columnas se pueden comprimir mucho más que los almacenes de datos basados en filas porque datos similares se almacenan secuencialmente en el disco. Amazon Redshift emplea múltiples técnicas de compresión y, a menudo, puede lograr una compresión significativa en comparación con los almacenes de datos de relaciones tradicionales.
Amazon Redshift no requiere índices ni vistas materializadas, por lo que requiere menos espacio que los sistemas de bases de datos relacionales tradicionales. Al cargar datos en una tabla vacía, Amazon Redshift toma muestras de sus datos automáticamente y selecciona la técnica de compresión más adecuada.Procesamiento masivo en paralelo
Amazon Redshift distribuye automáticamente los datos y carga la consulta en varios nodos. Amazon Redshift facilita la adición de nuevos nodos a su almacén de datos y esto nos permite lograr un rendimiento de consultas más rápido a medida que crece su almacén de datos.Funciones de desplazamiento al rojo
Las características de Redshift se detallan a continuación:
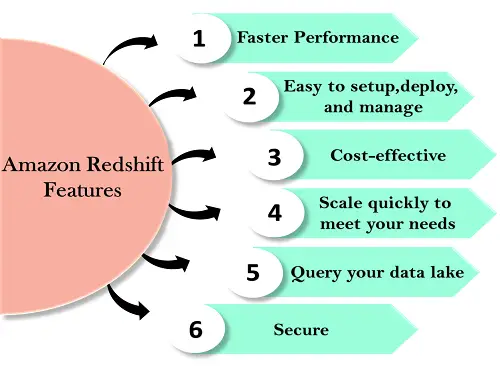
Fácil de configurar, implementar y administrar Aprovisionamiento automatizado
Redshift es fácil de configurar y operar. Puede implementar un nuevo almacén de datos con solo unos pocos clics en la consola de AWS y Redshift aprovisionará automáticamente la infraestructura por usted. En AWS, todas las tareas administrativas están automatizadas, como las copias de seguridad y la replicación, debe concentrarse en sus datos, no en la administración.Copias de seguridad automatizadas
Redshift realiza automáticamente una copia de seguridad de sus datos en S3. También puede replicar las instantáneas en S3 en otra región para cualquier recuperación ante desastres.Económico Sin costos iniciales, paga sobre la marcha
Amazon Redshift es el servicio de almacenamiento de datos más rentable, ya que solo debe pagar por lo que utiliza.
Sus costos comienzan con $0,25 por hora sin compromiso ni costos iniciales y pueden ampliarse hasta $250 por terabyte por año.
Amazon Redshift es el único servicio de almacenamiento de datos que ofrece precios On Demand sin costos iniciales y también ofrece precios de instancia reservada que ahorra hasta un 75 % al brindar un plazo de 1 a 3 años.Elija su tipo de nodo.
Puede elegir cualquiera de los dos nodos para optimizar el desplazamiento al rojo.Nodo de computación denso
El nodo de computación denso puede crear almacenes de datos de alto rendimiento mediante el uso de CPU rápidas, una gran cantidad de RAM y discos de estado sólido.Nodo de almacenamiento denso
Si desea reducir el costo, puede utilizar el nodo de almacenamiento denso. Crea un almacén de datos rentable mediante el uso de una unidad de disco duro más grande.Escale rápidamente para satisfacer sus necesidades. Almacenamiento de datos a escala de petabytes
Amazon Redshift aumenta o reduce automáticamente los nodos según los cambios necesarios. Con solo unos pocos clics en la consola de AWS o una sola llamada a la API, puede cambiar fácilmente la cantidad de nodos en un almacén de datos.Análisis de lagos de datos a escala de exabytes
Es una característica de Redshift que le permite ejecutar consultas en exabytes de datos en Amazon S3. Amazon S3 es un sistema de datos seguro y rentable para almacenar datos ilimitados en un formato abierto.Simultaneidad ilimitada
Es una característica de Redshift que significa que múltiples consultas pueden acceder a los mismos datos en Amazon S3. Le permite ejecutar consultas en varios nodos independientemente de la complejidad de una consulta o la cantidad de datos.Consulta tu lago de datos
Amazon Redshift es el único almacén de datos que se utiliza para consultar el lago de datos de Amazon S3 sin cargar datos. Esto proporciona flexibilidad al almacenar los datos a los que se accede con frecuencia en Redshift y los datos no estructurados o a los que se accede con poca frecuencia en Amazon S3.Seguro
Con un par de configuraciones de parámetros, puede configurar Redshift para que use SSL para proteger sus datos. También puede habilitar el cifrado, todos los datos escritos en el disco se cifrarán.Rendimiento más rápido
Amazon Redshift proporciona almacenamiento de datos en columnas, compresión y procesamiento paralelo para reducir la cantidad de E/S necesaria para realizar consultas. Esto mejora el rendimiento de las consultas.
OLAP
OLAP es un Sistema de procesamiento de análisis en línea utilizado por el corrimiento al rojo .
Ejemplo de transacción OLAP:
Supongamos que queremos calcular el beneficio neto para EMEA y Pacífico del producto de radio digital. Esto requiere extraer una gran cantidad de registros. Los siguientes son los registros necesarios para calcular una ganancia neta:
- Suma de Radios vendidas en EMEA.
- Sumatoria de Radios vendidas en Pacífico.
- Costo unitario de la radio en cada región.
- Precio de venta de cada radio.
- Precio de venta - costo unitario
Se requieren consultas complejas para recuperar los registros proporcionados anteriormente. Las bases de datos de almacenamiento de datos utilizan diferentes tipos de arquitectura tanto desde la perspectiva de la base de datos como desde la capa de infraestructura.
Configuración de desplazamiento al rojo

Redshift consta de dos tipos de nodos:
Nodo único: Un solo nodo almacena hasta 160 GB.
Multinodo: Un nodo múltiple es un nodo que consta de más de un nodo. Es de dos tipos:
Gestiona las conexiones de los clientes y recibe consultas. Un nodo líder recibe las consultas de las aplicaciones cliente, las analiza y desarrolla los planes de ejecución. Se coordina con la ejecución paralela de estos planes con el nodo de cómputo y combina los resultados intermedios de todos los nodos, y luego devuelve el resultado final a la aplicación cliente.
Un nodo de cálculo ejecuta los planes de ejecución y luego los resultados intermedios se envían al nodo líder para su agregación antes de enviarlos de regreso a la aplicación cliente. Puede tener hasta 128 nodos de cómputo.
Entendamos el concepto de nodo líder y nodos de cálculo a través de un ejemplo.

El almacén de Redshift es una colección de recursos informáticos conocidos como nodos, y estos nodos están organizados en un grupo conocido como clúster. Cada clúster se ejecuta en un motor Redshift que contiene una o más bases de datos.
Cuando lanza una instancia de Redshift, comienza con un único nodo de 160 GB de tamaño. Cuando desee crecer, puede agregar nodos adicionales para aprovechar el procesamiento paralelo. Tiene un nodo líder que gestiona los múltiples nodos. El nodo líder maneja la conexión del cliente, así como los nodos de computación. Almacena los datos en nodos informáticos y realiza la consulta.
Por qué Redshift es 10 veces más rápido
El desplazamiento al rojo es 10 veces más rápido por las siguientes razones:
En lugar de almacenar datos como una serie de filas, Amazon Redshift organiza los datos por columnas. Los sistemas basados en filas son ideales para el procesamiento de transacciones, mientras que los sistemas basados en columnas son ideales para el almacenamiento y análisis de datos, donde las consultas a menudo implican agregados realizados en grandes conjuntos de datos. Dado que solo se procesan las columnas involucradas en las consultas y los datos de las columnas se almacenan secuencialmente en un medio de almacenamiento, los sistemas basados en columnas requieren menos E/S, lo que mejora el rendimiento de las consultas.
Los almacenes de datos en columnas se pueden comprimir mucho más que los almacenes de datos basados en filas porque datos similares se almacenan secuencialmente en el disco. Amazon Redshift emplea múltiples técnicas de compresión y, a menudo, puede lograr una compresión significativa en comparación con los almacenes de datos de relaciones tradicionales.
Amazon Redshift no requiere índices ni vistas materializadas, por lo que requiere menos espacio que los sistemas de bases de datos relacionales tradicionales. Al cargar datos en una tabla vacía, Amazon Redshift toma muestras de sus datos automáticamente y selecciona la técnica de compresión más adecuada.
Amazon Redshift distribuye automáticamente los datos y carga la consulta en varios nodos. Amazon Redshift facilita la adición de nuevos nodos a su almacén de datos y esto nos permite lograr un rendimiento de consultas más rápido a medida que crece su almacén de datos.
Funciones de desplazamiento al rojo
Las características de Redshift se detallan a continuación:
java convierte caracteres a int

- Redshift es un servicio de almacenamiento de datos a escala de petabytes, rápido y potente, totalmente gestionado en la nube.
- Los clientes pueden usar Redshift por solo $0,25 por hora sin compromisos ni costos iniciales y escalar a un petabyte o más por $1000 por terabyte al año.
- Suma de Radios vendidas en EMEA.
- Sumatoria de Radios vendidas en Pacífico.
- Costo unitario de la radio en cada región.
- Precio de venta de cada radio.
- Precio de venta - costo unitario
Redshift es fácil de configurar y operar. Puede implementar un nuevo almacén de datos con solo unos pocos clics en la consola de AWS y Redshift aprovisionará automáticamente la infraestructura por usted. En AWS, todas las tareas administrativas están automatizadas, como las copias de seguridad y la replicación, debe concentrarse en sus datos, no en la administración.
Redshift realiza automáticamente una copia de seguridad de sus datos en S3. También puede replicar las instantáneas en S3 en otra región para cualquier recuperación ante desastres.
Amazon Redshift es el servicio de almacenamiento de datos más rentable, ya que solo debe pagar por lo que utiliza.
Sus costos comienzan con
OLAP
OLAP es un Sistema de procesamiento de análisis en línea utilizado por el corrimiento al rojo .
Ejemplo de transacción OLAP:
Supongamos que queremos calcular el beneficio neto para EMEA y Pacífico del producto de radio digital. Esto requiere extraer una gran cantidad de registros. Los siguientes son los registros necesarios para calcular una ganancia neta:
Se requieren consultas complejas para recuperar los registros proporcionados anteriormente. Las bases de datos de almacenamiento de datos utilizan diferentes tipos de arquitectura tanto desde la perspectiva de la base de datos como desde la capa de infraestructura.
Configuración de desplazamiento al rojo
Redshift consta de dos tipos de nodos:
Nodo único: Un solo nodo almacena hasta 160 GB.
Multinodo: Un nodo múltiple es un nodo que consta de más de un nodo. Es de dos tipos:
Gestiona las conexiones de los clientes y recibe consultas. Un nodo líder recibe las consultas de las aplicaciones cliente, las analiza y desarrolla los planes de ejecución. Se coordina con la ejecución paralela de estos planes con el nodo de cómputo y combina los resultados intermedios de todos los nodos, y luego devuelve el resultado final a la aplicación cliente.
Un nodo de cálculo ejecuta los planes de ejecución y luego los resultados intermedios se envían al nodo líder para su agregación antes de enviarlos de regreso a la aplicación cliente. Puede tener hasta 128 nodos de cómputo.
Entendamos el concepto de nodo líder y nodos de cálculo a través de un ejemplo.
El almacén de Redshift es una colección de recursos informáticos conocidos como nodos, y estos nodos están organizados en un grupo conocido como clúster. Cada clúster se ejecuta en un motor Redshift que contiene una o más bases de datos.
Cuando lanza una instancia de Redshift, comienza con un único nodo de 160 GB de tamaño. Cuando desee crecer, puede agregar nodos adicionales para aprovechar el procesamiento paralelo. Tiene un nodo líder que gestiona los múltiples nodos. El nodo líder maneja la conexión del cliente, así como los nodos de computación. Almacena los datos en nodos informáticos y realiza la consulta.
Por qué Redshift es 10 veces más rápido
El desplazamiento al rojo es 10 veces más rápido por las siguientes razones:
En lugar de almacenar datos como una serie de filas, Amazon Redshift organiza los datos por columnas. Los sistemas basados en filas son ideales para el procesamiento de transacciones, mientras que los sistemas basados en columnas son ideales para el almacenamiento y análisis de datos, donde las consultas a menudo implican agregados realizados en grandes conjuntos de datos. Dado que solo se procesan las columnas involucradas en las consultas y los datos de las columnas se almacenan secuencialmente en un medio de almacenamiento, los sistemas basados en columnas requieren menos E/S, lo que mejora el rendimiento de las consultas.
Los almacenes de datos en columnas se pueden comprimir mucho más que los almacenes de datos basados en filas porque datos similares se almacenan secuencialmente en el disco. Amazon Redshift emplea múltiples técnicas de compresión y, a menudo, puede lograr una compresión significativa en comparación con los almacenes de datos de relaciones tradicionales.
Amazon Redshift no requiere índices ni vistas materializadas, por lo que requiere menos espacio que los sistemas de bases de datos relacionales tradicionales. Al cargar datos en una tabla vacía, Amazon Redshift toma muestras de sus datos automáticamente y selecciona la técnica de compresión más adecuada.
Amazon Redshift distribuye automáticamente los datos y carga la consulta en varios nodos. Amazon Redshift facilita la adición de nuevos nodos a su almacén de datos y esto nos permite lograr un rendimiento de consultas más rápido a medida que crece su almacén de datos.
Funciones de desplazamiento al rojo
Las características de Redshift se detallan a continuación:
Redshift es fácil de configurar y operar. Puede implementar un nuevo almacén de datos con solo unos pocos clics en la consola de AWS y Redshift aprovisionará automáticamente la infraestructura por usted. En AWS, todas las tareas administrativas están automatizadas, como las copias de seguridad y la replicación, debe concentrarse en sus datos, no en la administración.
Redshift realiza automáticamente una copia de seguridad de sus datos en S3. También puede replicar las instantáneas en S3 en otra región para cualquier recuperación ante desastres.
Amazon Redshift es el servicio de almacenamiento de datos más rentable, ya que solo debe pagar por lo que utiliza.
Sus costos comienzan con $0,25 por hora sin compromiso ni costos iniciales y pueden ampliarse hasta $250 por terabyte por año.
Amazon Redshift es el único servicio de almacenamiento de datos que ofrece precios On Demand sin costos iniciales y también ofrece precios de instancia reservada que ahorra hasta un 75 % al brindar un plazo de 1 a 3 años.
Puede elegir cualquiera de los dos nodos para optimizar el desplazamiento al rojo.
El nodo de computación denso puede crear almacenes de datos de alto rendimiento mediante el uso de CPU rápidas, una gran cantidad de RAM y discos de estado sólido.
Si desea reducir el costo, puede utilizar el nodo de almacenamiento denso. Crea un almacén de datos rentable mediante el uso de una unidad de disco duro más grande.
Amazon Redshift aumenta o reduce automáticamente los nodos según los cambios necesarios. Con solo unos pocos clics en la consola de AWS o una sola llamada a la API, puede cambiar fácilmente la cantidad de nodos en un almacén de datos.
Es una característica de Redshift que le permite ejecutar consultas en exabytes de datos en Amazon S3. Amazon S3 es un sistema de datos seguro y rentable para almacenar datos ilimitados en un formato abierto.
Es una característica de Redshift que significa que múltiples consultas pueden acceder a los mismos datos en Amazon S3. Le permite ejecutar consultas en varios nodos independientemente de la complejidad de una consulta o la cantidad de datos.
Amazon Redshift es el único almacén de datos que se utiliza para consultar el lago de datos de Amazon S3 sin cargar datos. Esto proporciona flexibilidad al almacenar los datos a los que se accede con frecuencia en Redshift y los datos no estructurados o a los que se accede con poca frecuencia en Amazon S3.
Con un par de configuraciones de parámetros, puede configurar Redshift para que use SSL para proteger sus datos. También puede habilitar el cifrado, todos los datos escritos en el disco se cifrarán.
Amazon Redshift proporciona almacenamiento de datos en columnas, compresión y procesamiento paralelo para reducir la cantidad de E/S necesaria para realizar consultas. Esto mejora el rendimiento de las consultas.
Amazon Redshift es el único servicio de almacenamiento de datos que ofrece precios On Demand sin costos iniciales y también ofrece precios de instancia reservada que ahorra hasta un 75 % al brindar un plazo de 1 a 3 años.
Puede elegir cualquiera de los dos nodos para optimizar el desplazamiento al rojo.
El nodo de computación denso puede crear almacenes de datos de alto rendimiento mediante el uso de CPU rápidas, una gran cantidad de RAM y discos de estado sólido.
Si desea reducir el costo, puede utilizar el nodo de almacenamiento denso. Crea un almacén de datos rentable mediante el uso de una unidad de disco duro más grande.
Amazon Redshift aumenta o reduce automáticamente los nodos según los cambios necesarios. Con solo unos pocos clics en la consola de AWS o una sola llamada a la API, puede cambiar fácilmente la cantidad de nodos en un almacén de datos.
Es una característica de Redshift que le permite ejecutar consultas en exabytes de datos en Amazon S3. Amazon S3 es un sistema de datos seguro y rentable para almacenar datos ilimitados en un formato abierto.
Es una característica de Redshift que significa que múltiples consultas pueden acceder a los mismos datos en Amazon S3. Le permite ejecutar consultas en varios nodos independientemente de la complejidad de una consulta o la cantidad de datos.
Amazon Redshift es el único almacén de datos que se utiliza para consultar el lago de datos de Amazon S3 sin cargar datos. Esto proporciona flexibilidad al almacenar los datos a los que se accede con frecuencia en Redshift y los datos no estructurados o a los que se accede con poca frecuencia en Amazon S3.
Con un par de configuraciones de parámetros, puede configurar Redshift para que use SSL para proteger sus datos. También puede habilitar el cifrado, todos los datos escritos en el disco se cifrarán.
Amazon Redshift proporciona almacenamiento de datos en columnas, compresión y procesamiento paralelo para reducir la cantidad de E/S necesaria para realizar consultas. Esto mejora el rendimiento de las consultas.