cuidador del zoológico es un servicio de coordinación distribuido de código abierto para aplicaciones distribuidas. Expone un conjunto simple de primitivas para implementar servicios de nivel superior para sincronización, mantenimiento de configuración y agrupación y denominación.
En un sistema distribuido, existen múltiples nodos o máquinas que necesitan comunicarse entre sí y coordinar sus acciones. ZooKeeper proporciona una manera de garantizar que estos nodos se conozcan entre sí y puedan coordinar sus acciones. Para ello, mantiene un árbol jerárquico de nodos de datos llamado nodos , que se puede utilizar para almacenar y recuperar datos y mantener información de estado. ZooKeeper proporciona un conjunto de primitivas, como bloqueos, barreras y colas, que pueden usarse para coordinar las acciones de los nodos en un sistema distribuido. También proporciona características como elección de líder, conmutación por error y recuperación, que pueden ayudar a garantizar que el sistema sea resistente a las fallas. ZooKeeper se usa ampliamente en sistemas distribuidos como Hadoop, Kafka y HBase, y se ha convertido en un componente esencial de muchas aplicaciones distribuidas.
¿Por qué lo necesitamos?
- Servicios de coordinación : La integración/comunicación de servicios en un entorno distribuido.
- Los servicios de coordinación son complejos de lograr. Son especialmente propensos a errores como condiciones de carrera y punto muerto.
- Condición de carrera -Dos o más sistemas intentando realizar alguna tarea.
- Puntos muertos – Dos o más operaciones se esperan una a la otra.
- Para facilitar la coordinación entre entornos distribuidos, a los desarrolladores se les ocurrió una idea llamada zookeeper para no tener que liberar a las aplicaciones distribuidas de la responsabilidad de implementar servicios de coordinación desde cero.
¿Qué es el sistema distribuido?
- Múltiples sistemas informáticos trabajando en un solo problema.
- Es una red que consta de computadoras autónomas que se conectan mediante middleware distribuido.
- Características clave : Concurrente, compartido de recursos, independiente, global, mayor tolerancia a fallas y relación precio/rendimiento es mucho mejor.
- Objetivo fundamental s: Transparencia, Confiabilidad, Rendimiento, Escalabilidad.
- Desafíos : Seguridad, Fallo, Coordinación y uso compartido de recursos.
Desafío de coordinación
- ¿Por qué la coordinación en un sistema distribuido es el problema más difícil?
- Gestión de coordinación o configuración para una aplicación distribuida que tiene muchos sistemas.
- Nodo maestro donde se almacenan los datos del cluster.
- Los nodos trabajadores o esclavos obtienen los datos de este nodo maestro.
- punto único de fallo.
- La sincronización no es fácil.
- Se necesita un diseño e implementación cuidadosos.
Cuidador del zoológico apache
Apache Zookeeper es un servicio de coordinación distribuido de código abierto para sistemas distribuidos. Proporciona un lugar central para que las aplicaciones distribuidas almacenen datos, se comuniquen entre sí y coordinen actividades. Zookeeper se utiliza en sistemas distribuidos para coordinar procesos y servicios distribuidos. Proporciona un modelo de datos simple estructurado en árbol, una API simple y un protocolo distribuido para garantizar la coherencia y disponibilidad de los datos. Zookeeper está diseñado para ser altamente confiable y tolerante a fallas, y puede manejar altos niveles de rendimiento de lectura y escritura.
Zookeeper está implementado en Java y se usa ampliamente en sistemas distribuidos, particularmente en el ecosistema Hadoop. Es un proyecto de Apache Software Foundation y se publica bajo la licencia Apache 2.0.
Arquitectura de Zookeeper
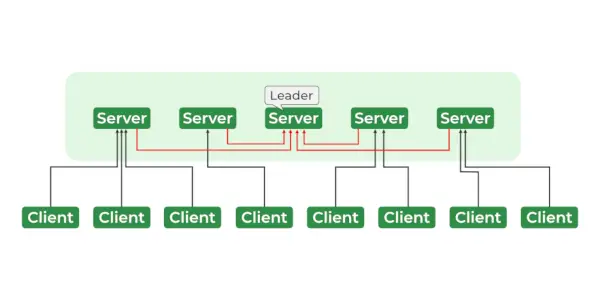
Servicios de cuidador del zoológico
La arquitectura de ZooKeeper consta de una jerarquía de nodos llamados znodes, organizados en una estructura similar a un árbol. Cada znode puede almacenar datos y tiene un conjunto de permisos que controlan el acceso al znode. Los znodes están organizados en un espacio de nombres jerárquico, similar a un sistema de archivos. En la raíz de la jerarquía está el znode raíz, y todos los demás znodes son hijos del znode raíz. La jerarquía es similar a la jerarquía de un sistema de archivos, donde cada znode puede tener hijos y nietos, etc.
Componentes importantes en Zookeeper
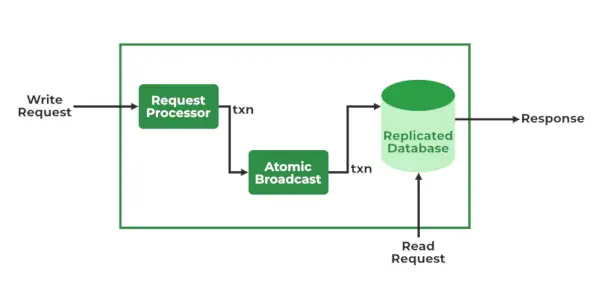
Servicios de ZooKeeper
- Líder y seguidor
- Procesador de solicitudes – Activo en el nodo líder y es responsable de procesar las solicitudes de escritura. Después del procesamiento, envía cambios a los nodos seguidores.
- Transmisión atómica – Presente tanto en el nodo líder como en el nodo seguidor. Se encarga de enviar los cambios a otros Nodos.
- Bases de datos en memoria (Bases de datos replicadas): se encarga de almacenar los datos en el cuidador del zoológico. Cada nodo contiene sus propias bases de datos. Los datos también se escriben en el sistema de archivos, lo que proporciona capacidad de recuperación en caso de cualquier problema con el clúster.
Otros componentes
- Cliente – Uno de los nodos de nuestro clúster de aplicaciones distribuidas. Acceder a la información del servidor. Cada cliente envía un mensaje al servidor para informarle que el cliente está vivo.
- Servidor – Proporciona todos los servicios al cliente. Da reconocimiento al cliente.
- Conjunto – Grupo de servidores Zookeeper. El número mínimo de nodos necesarios para formar un conjunto es 3.
Modelo de datos del cuidador del zoológico
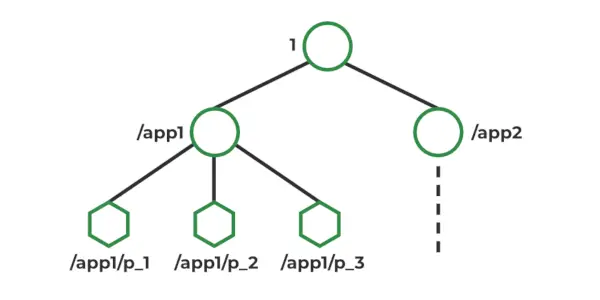
Modelo de datos de ZooKeeper
En Zookeeper, los datos se almacenan en un espacio de nombres jerárquico, similar a un sistema de archivos. Cada nodo en el espacio de nombres se llama Znode y puede almacenar datos y tener hijos. Los Znodes son similares a archivos y directorios en un sistema de archivos. Zookeeper proporciona una API sencilla para crear, leer, escribir y eliminar Znodes. También proporciona mecanismos para detectar cambios en los datos almacenados en Znodes, como relojes y activadores. Znodes mantiene una estructura de estadísticas que incluye: número de versión, ACL, marca de tiempo, longitud de datos
Tipos de nodos Z :
- Persistencia : Vivos hasta que se eliminen explícitamente.
- Efímero : Activo hasta que la conexión del cliente esté activa.
- Secuencial : Ya sea persistente o efímero.
¿Por qué necesitamos ZooKeeper en Hadoop?
Zookeeper se utiliza para administrar y coordinar los nodos en un clúster de Hadoop, incluidos NameNode, DataNode y ResourceManager. En un clúster de Hadoop, Zookeeper ayuda a:
- Mantener la información de configuración: Zookeeper almacena la información de configuración del clúster de Hadoop, incluida la ubicación de NameNode, DataNode y ResourceManager.
- Administre el estado del clúster: Zookeeper rastrea el estado de los nodos en el clúster de Hadoop y puede usarse para detectar cuando un nodo falla o deja de estar disponible.
- Coordinar procesos distribuidos: Zookeeper se puede utilizar para coordinar procesos distribuidos, como la programación de trabajos y la asignación de recursos, entre los nodos de un clúster de Hadoop.
Zookeeper ayuda a garantizar la disponibilidad y confiabilidad de un clúster de Hadoop al proporcionar un servicio de coordinación central para los nodos del clúster.
¿Cómo funciona ZooKeeper en Hadoop?
ZooKeeper opera como un sistema de archivos distribuido y expone un conjunto simple de API que permiten a los clientes leer y escribir datos en el sistema de archivos. Almacena sus datos en una estructura en forma de árbol llamada znode, que puede considerarse como un archivo o directorio en un sistema de archivos tradicional. ZooKeeper utiliza un algoritmo de consenso para garantizar que todos sus servidores tengan una vista coherente de los datos almacenados en Znodes. Esto significa que si un cliente escribe datos en un znode, esos datos se replicarán en todos los demás servidores del conjunto ZooKeeper.
Una característica importante de ZooKeeper es su capacidad para respaldar la noción de reloj. Un reloj permite a un cliente registrarse para recibir notificaciones cuando cambian los datos almacenados en un znode. Esto puede resultar útil para monitorear cambios en los datos almacenados en ZooKeeper y reaccionar a esos cambios en un sistema distribuido.
En Hadoop, ZooKeeper se utiliza para diversos fines, entre ellos:
- Almacenamiento de información de configuración: ZooKeeper se utiliza para almacenar información de configuración compartida por múltiples componentes de Hadoop. Por ejemplo, podría usarse para almacenar las ubicaciones de NameNodes en un clúster de Hadoop o las direcciones de los nodos JobTracker.
- Proporcionar sincronización distribuida: ZooKeeper se utiliza para coordinar las actividades de varios componentes de Hadoop y garantizar que trabajen juntos de manera consistente. Por ejemplo, podría usarse para garantizar que solo un NameNode esté activo a la vez en un clúster de Hadoop.
- Mantenimiento de nombres: ZooKeeper se utiliza para mantener un servicio de nombres centralizado para los componentes de Hadoop. Esto puede resultar útil para identificar y localizar recursos en un sistema distribuido.
ZooKeeper es un componente esencial de Hadoop y desempeña un papel crucial en la coordinación de la actividad de sus diversos subcomponentes.
Lectura y escritura en Apache Zookeeper
ZooKeeper proporciona una interfaz sencilla y confiable para leer y escribir datos. Los datos se almacenan en un espacio de nombres jerárquico, similar a un sistema de archivos, con nodos llamados znodes. Cada znode puede almacenar datos y tener znodes secundarios. Los clientes de ZooKeeper pueden leer y escribir datos en estos znodes utilizando los métodos getData() y setData(), respectivamente. A continuación se muestra un ejemplo de lectura y escritura de datos utilizando la API de Java de ZooKeeper:
Java
// Connect to the ZooKeeper ensemble> ZooKeeper zk =>new> ZooKeeper(>'localhost:2181'>,>3000>,>null>);> // Write data to the znode '/myZnode'> String path =>'/myZnode'>;> String data =>'hello world'>;> zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);> // Read data from the znode '/myZnode'> byte>[] bytes = zk.getData(path,>false>,>null>);> String readData =>new> String(bytes);> // Prints 'hello world'> System.out.println(readData);> // Closing the connection> // to the ZooKeeper ensemble> zk.close();> |
>
>
Python3
from> kazoo.client>import> KazooClient> # Connect to ZooKeeper> zk>=> KazooClient(hosts>=>'localhost:2181'>)> zk.start()> # Create a node with some data> zk.ensure_path(>'/gfg_node'>)> zk.>set>(>'/gfg_node'>, b>'some_data'>)> # Read the data from the node> data, stat>=> zk.get(>'/gfg_node'>)> print>(data)> # Stop the connection to ZooKeeper> zk.stop()> |
>
Actor Rekha
>
Sesión y relojes
Sesión
- Las solicitudes en una sesión se ejecutan en orden FIFO.
- Una vez establecida la sesión, el ID de sesión se asigna al cliente.
- El cliente envía latidos del corazon para mantener la sesión válida
- El tiempo de espera de la sesión generalmente se representa en milisegundos.
Relojes
- Los relojes son mecanismos para que los clientes reciban notificaciones sobre los cambios en Zookeeper.
- El cliente puede mirar mientras lee un znode en particular.
- Los cambios de Znodes son modificaciones de datos asociados con los znodes o cambios en los hijos del znode.
- Los relojes se activan sólo una vez.
- Si la sesión caduca, las vigilancias también se eliminan.