Leemos las estructuras de datos lineales como una matriz, una lista vinculada, una pila y una cola en las que todos los elementos están organizados de manera secuencial. Las diferentes estructuras de datos se utilizan para diferentes tipos de datos.
Se consideran algunos factores para elegir la estructura de datos:
Un árbol También es una de las estructuras de datos que representan datos jerárquicos. Supongamos que queremos mostrar los empleados y sus puestos en forma jerárquica, entonces se puede representar como se muestra a continuación:
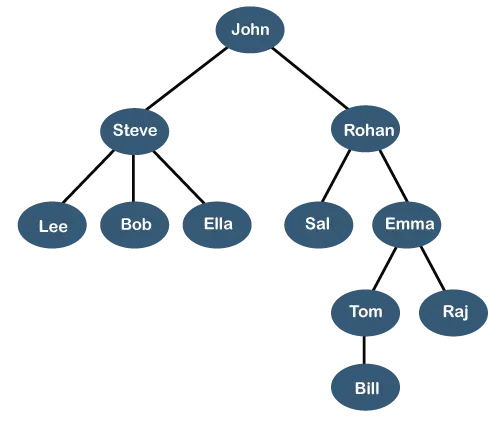
El árbol de arriba muestra el jerarquía organizacional de alguna empresa. En la estructura anterior, John es el CEO de la empresa, y John tiene dos subordinados directos nombrados como esteban y rohan . Steve tiene tres subordinados directos llamados Lee, Bob, Ella dónde esteban es un gerente. Bob tiene dos subordinados directos llamados Deberá y emma . emma tiene dos subordinados directos nombrados Tomás y Raj . Tom tiene un subordinado directo llamado Factura . Esta estructura lógica particular se conoce como Árbol . Su estructura es similar a la del árbol real, por eso se le llama Árbol . En esta estructura, el raíz está en la parte superior y sus ramas se mueven hacia abajo. Por tanto, podemos decir que la estructura de datos de Árbol es una forma eficaz de almacenar los datos de forma jerárquica.
Entendamos algunos puntos clave de la estructura de datos del árbol.
- Una estructura de datos de árbol se define como una colección de objetos o entidades conocidas como nodos que están vinculados entre sí para representar o simular una jerarquía.
- Una estructura de datos de árbol es una estructura de datos no lineal porque no se almacena de manera secuencial. Es una estructura jerárquica ya que los elementos de un árbol están organizados en múltiples niveles.
- En la estructura de datos del árbol, el nodo superior se conoce como nodo raíz. Cada nodo contiene algunos datos y los datos pueden ser de cualquier tipo. En la estructura de árbol anterior, el nodo contiene el nombre del empleado, por lo que el tipo de datos sería una cadena.
- Cada nodo contiene algunos datos y el enlace o referencia de otros nodos que pueden denominarse hijos.
Algunos términos básicos utilizados en la estructura de datos del árbol.
Consideremos la estructura de árbol, que se muestra a continuación:

En la estructura anterior, cada nodo está etiquetado con algún número. Cada flecha que se muestra en la figura anterior se conoce como enlace entre los dos nodos.
Propiedades de la estructura de datos del árbol

Según las propiedades de la estructura de datos del árbol, los árboles se clasifican en varias categorías.
Implementación del árbol
La estructura de datos del árbol se puede crear creando los nodos dinámicamente con la ayuda de los punteros. El árbol en la memoria se puede representar como se muestra a continuación:

La figura anterior muestra la representación de la estructura de datos de árbol en la memoria. En la estructura anterior, el nodo contiene tres campos. El segundo campo almacena los datos; el primer campo almacena la dirección del hijo izquierdo y el tercer campo almacena la dirección del hijo derecho.
En programación, la estructura de un nodo se puede definir como:
struct node { int data; struct node *left; struct node *right; } La estructura anterior solo se puede definir para los árboles binarios porque el árbol binario puede tener como máximo dos hijos y los árboles genéricos pueden tener más de dos hijos. La estructura del nodo para árboles genéricos sería diferente en comparación con el árbol binario.
Aplicaciones de los árboles
Las siguientes son las aplicaciones de los árboles:
Tipos de estructura de datos de árbol
Los siguientes son los tipos de estructura de datos de árbol:

Puede haber norte Número de subárboles en un árbol general. En el árbol general, los subárboles están desordenados ya que los nodos del subárbol no se pueden ordenar.
Todo árbol no vacío tiene un borde descendente, y estos bordes están conectados a los nodos conocidos como nodos secundarios . El nodo raíz está etiquetado con el nivel 0. Los nodos que tienen el mismo padre se conocen como hermanos .

Para saber más sobre el árbol binario, haga clic en el enlace que figura a continuación:
https://www.javatpoint.com/binary-tree
Cada nodo en el subárbol izquierdo debe contener un valor menor que el valor del nodo raíz, y el valor de cada nodo en el subárbol derecho debe ser mayor que el valor del nodo raíz.
Se puede crear un nodo con la ayuda de un tipo de datos definido por el usuario conocido como estructura, Como se muestra abajo:
struct node { int data; struct node *left; struct node *right; } Lo anterior es la estructura de nodo con tres campos: campo de datos, el segundo campo es el puntero izquierdo del tipo de nodo y el tercer campo es el puntero derecho del tipo de nodo.
Para saber más sobre el árbol de búsqueda binaria, haga clic en el enlace que figura a continuación:
https://www.javatpoint.com/binary-search-tree
Es uno de los tipos de árbol binario, o podemos decir que es una variante del árbol binario de búsqueda. El árbol AVL satisface la propiedad del árbol binario así como de la árbol de búsqueda binaria . Es un árbol de búsqueda binario autoequilibrado que fue inventado por Adelson Velsky Lindas . Aquí, autoequilibrio significa equilibrar las alturas del subárbol izquierdo y del subárbol derecho. Este equilibrio se mide en términos de factor de equilibrio .
Podemos considerar un árbol como un árbol AVL si el árbol obedece al árbol de búsqueda binario así como a un factor de equilibrio. El factor de equilibrio se puede definir como el diferencia entre la altura del subárbol izquierdo y la altura del subárbol derecho . El valor del factor de equilibrio debe ser 0, -1 o 1; por lo tanto, cada nodo en el árbol AVL debe tener el valor del factor de equilibrio como 0, -1 o 1.
Para saber más sobre el árbol AVL, haga clic en el enlace que figura a continuación:
https://www.javatpoint.com/avl-tree
El árbol rojo-negro es el árbol de búsqueda binario. El requisito previo del árbol Rojo-Negro es que debemos conocer el árbol de búsqueda binario. En un árbol de búsqueda binario, el valor del subárbol izquierdo debe ser menor que el valor de ese nodo y el valor del subárbol derecho debe ser mayor que el valor de ese nodo. Como sabemos, la complejidad temporal de la búsqueda binaria en el caso promedio es log2n, el mejor caso es O(1) y el peor caso es O(n).
Cuando se realiza cualquier operación en el árbol, queremos que nuestro árbol esté equilibrado para que todas las operaciones como búsqueda, inserción, eliminación, etc., tomen menos tiempo, y todas estas operaciones tendrán una complejidad temporal de registro2norte.
El árbol rojo-negro es un árbol de búsqueda binario autoequilibrado. El árbol AVL también es un árbol de búsqueda binaria de equilibrio de altura. ¿Por qué necesitamos un árbol rojo-negro? . En el árbol AVL, no sabemos cuántas rotaciones se necesitarían para equilibrar el árbol, pero en el árbol Rojo-negro, se requieren un máximo de 2 rotaciones para equilibrar el árbol. Contiene un bit adicional que representa el color rojo o negro de un nodo para garantizar el equilibrio del árbol.
son ejemplos de modelos
La estructura de datos del árbol de distribución también es un árbol de búsqueda binaria en el que el elemento al que se accedió recientemente se coloca en la posición raíz del árbol mediante la realización de algunas operaciones de rotación. Aquí, esparciendo significa el nodo al que se accedió recientemente. Es un autoequilibrio árbol de búsqueda binaria que no tiene ninguna condición de equilibrio explícita como AVL árbol.
Podría existir la posibilidad de que la altura del árbol de distribución no esté equilibrada, es decir, la altura de los subárboles izquierdo y derecho puede diferir, pero las operaciones en el árbol de distribución siguen el orden de calma tiempo donde norte es el número de nodos.
El árbol de distribución es un árbol equilibrado, pero no puede considerarse como un árbol de altura equilibrada porque después de cada operación, se realiza una rotación que conduce a un árbol equilibrado.
La estructura de datos Treap proviene de la estructura de datos Tree y Heap. Por lo tanto, comprende las propiedades de las estructuras de datos de árbol y montón. En el árbol de búsqueda binaria, cada nodo del subárbol izquierdo debe ser igual o menor que el valor del nodo raíz y cada nodo del subárbol derecho debe ser igual o mayor que el valor del nodo raíz. En la estructura de datos del montón, los subárboles derecho e izquierdo contienen claves más grandes que la raíz; por lo tanto, podemos decir que el nodo raíz contiene el valor más bajo.
En la estructura de datos treap, cada nodo tiene ambos llave y prioridad donde la clave se deriva del árbol de búsqueda binaria y la prioridad se deriva de la estructura de datos del montón.
El Tragar La estructura de datos sigue dos propiedades que se detallan a continuación:
- Hijo derecho de un nodo>=nodo actual e hijo izquierdo de un nodo<=current node (binary tree)< li>
- Los hijos de cualquier subárbol deben ser mayores que el nodo (montón)
El árbol B es un equilibrado. m-way árbol donde metro define el orden del árbol. Hasta ahora, leemos que el nodo contiene solo una clave, pero el árbol b puede tener más de una clave y más de 2 hijos. Siempre mantiene los datos ordenados. En el árbol binario, es posible que los nodos hoja puedan estar en diferentes niveles, pero en el árbol b, todos los nodos hoja deben estar en el mismo nivel.
Si el orden es m, entonces el nodo tiene las siguientes propiedades:
- Cada nodo en un árbol b puede tener un máximo metro niños
- Para un mínimo de hijos, un nodo hoja tiene 0 hijos, el nodo raíz tiene un mínimo de 2 hijos y el nodo interno tiene un techo mínimo de m/2 hijos. Por ejemplo, el valor de m es 5, lo que significa que un nodo puede tener 5 hijos y los nodos internos pueden contener un máximo de 3 hijos.
- Cada nodo tiene claves máximas (m-1).
El nodo raíz debe contener al menos 1 clave y todos los demás nodos deben contener al menos techo de m/2 menos 1 llaves.