¿Qué es la caché LRU?
Los algoritmos de reemplazo de caché están diseñados de manera eficiente para reemplazar el caché cuando el espacio está lleno. El Menos usado recientemente (LRU) es uno de esos algoritmos. Como sugiere el nombre, cuando la memoria caché está llena, LRU selecciona los datos que se utilizaron menos recientemente y los elimina para dejar espacio para los nuevos datos. La prioridad de los datos en la caché cambia según la necesidad de esos datos, es decir, si algunos datos se recuperan o actualizan recientemente, la prioridad de esos datos se cambiará y se asignará a la prioridad más alta, y la prioridad de los datos disminuirá si permanece sin utilizar operaciones después de las operaciones.
Tabla de contenidos
- ¿Qué es la caché LRU?
- Operaciones en caché LRU:
- Funcionamiento de la caché LRU:
- Formas de implementar la caché LRU:
- Implementación de caché LRU usando Queue y Hashing:
- Implementación de caché LRU mediante lista doblemente enlazada y hash:
- Implementación de caché LRU usando Deque y Hashmap:
- Implementación de caché LRU usando Stack & Hashmap:
- Caché LRU usando implementación de contador:
- Implementación de caché LRU mediante actualizaciones diferidas:
- Análisis de complejidad de la caché LRU:
- Ventajas del caché LRU:
- Desventajas del caché LRU:
- Aplicación del mundo real de LRU Cache:
LRU El algoritmo es un problema estándar y puede tener variaciones según las necesidades, por ejemplo, en los sistemas operativos. LRU juega un papel crucial ya que puede usarse como algoritmo de reemplazo de páginas para minimizar los errores de página.
Operaciones en caché LRU:
- LRUCache (Capacidad c): Inicialice la caché LRU con capacidad de tamaño positivo C.
- obtener la clave) : Devuelve el valor de la clave ' k' si está presente en el caché, de lo contrario devuelve -1. También actualiza la prioridad de los datos en la caché LRU.
- poner (clave, valor): Actualice el valor de la clave si esa clave existe; de lo contrario, agregue el par clave-valor al caché. Si la cantidad de claves excedió la capacidad de la caché LRU, descarte la clave utilizada menos recientemente.
Funcionamiento de la caché LRU:
Supongamos que tenemos un caché LRU de capacidad 3 y nos gustaría realizar las siguientes operaciones:
- Coloque (clave = 1, valor = A) en el caché
- Coloque (clave = 2, valor = B) en el caché
- Coloque (clave = 3, valor = C) en el caché
- Obtener (clave = 2) del caché
- Obtener (clave = 4) del caché
- Coloque (clave = 4, valor = D) en el caché
- Coloque (clave = 3, valor = E) en el caché
- Obtener (clave = 4) del caché
- Coloque (clave = 1, valor = A) en el caché
Las operaciones anteriores se realizan una tras otra como se muestra en la siguiente imagen:
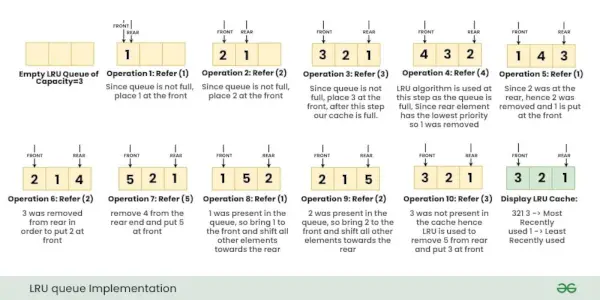
ordenar matriz en java
Explicación detallada de cada operación:
- Poner (clave 1, valor A) : Dado que la caché LRU tiene una capacidad vacía = 3, no hay necesidad de ningún reemplazo y colocamos {1: A} en la parte superior, es decir, {1: A} tiene la prioridad más alta.
- Poner (clave 2, valor B) : Dado que la caché LRU tiene una capacidad vacía = 2, nuevamente no hay necesidad de ningún reemplazo, pero ahora {2: B} tiene la prioridad más alta y la prioridad de {1: A} disminuye.
- Poner (clave 3, valor C) : Todavía hay 1 espacio vacío en el caché, por lo tanto, coloque {3: C} sin ningún reemplazo, observe que ahora el caché está lleno y el orden actual de prioridad de mayor a menor es {3:C}, {2:B }, {1:A}.
- Obtener (clave 2) : Ahora, devuelve el valor de clave=2 durante esta operación, además, dado que se usa clave=2, ahora el nuevo orden de prioridad es {2:B}, {3:C}, {1:A}
- Obtener (clave 4): Observe que la clave 4 no está presente en el caché, devolvemos '-1' para esta operación.
- Poner (clave 4, valor D) : Observe que el caché está LLENO, ahora use el algoritmo LRU para determinar qué clave se usó menos recientemente. Dado que {1:A} tenía la menor prioridad, elimine {1:A} de nuestro caché y coloque {4:D} en el caché. Observe que el nuevo orden de prioridad es {4:D}, {2:B}, {3:C}
- Poner (clave 3, valor E) : Dado que la clave = 3 ya estaba presente en el caché con valor = C, esta operación no resultará en la eliminación de ninguna clave, sino que actualizará el valor de la clave = 3 a ' Y' . Ahora, el nuevo orden de prioridad será {3:E}, {4:D}, {2:B}
- Obtener (clave 4) : Devuelve el valor de clave=4. Ahora, la nueva prioridad será {4:D}, {3:E}, {2:B}
- Poner (clave 1, valor A) : Dado que nuestro caché está LLENO, use nuestro algoritmo LRU para determinar qué clave se usó menos recientemente y, dado que {2:B} tenía la menor prioridad, elimine {2:B} de nuestro caché y coloque {1:A} en el cache. Ahora, el nuevo orden de prioridad es {1:A}, {4:D}, {3:E}
Formas de implementar la caché LRU:
La caché LRU se puede implementar de diversas formas y cada programador puede elegir un enfoque diferente. Sin embargo, a continuación se muestran los enfoques más utilizados:
- LRU usando cola y hash
- LRU usando Lista doblemente enlazada + hash
- LRU usando Deque
- LRU usando pila
- LRU usando Implementación contraria
- LRU usando actualizaciones diferidas
Implementación de caché LRU usando Queue y Hashing:
Usamos dos estructuras de datos para implementar un caché LRU.
- Cola se implementa utilizando una lista doblemente enlazada. El tamaño máximo de la cola será igual al número total de fotogramas disponibles (tamaño de caché). Las páginas utilizadas más recientemente estarán cerca del extremo frontal y las páginas utilizadas menos recientemente estarán cerca del extremo posterior.
- un hachís con el número de página como clave y la dirección del nodo de cola correspondiente como valor.
Cuando se hace referencia a una página, la página requerida puede estar en la memoria. Si está en la memoria, debemos separar el nodo de la lista y llevarlo al frente de la cola.
Si la página requerida no está en la memoria, la traemos a la memoria. En palabras simples, agregamos un nuevo nodo al frente de la cola y actualizamos la dirección del nodo correspondiente en el hash. Si la cola está llena, es decir, todos los fotogramas están llenos, eliminamos un nodo de la parte posterior de la cola y agregamos el nuevo nodo al frente de la cola.
Ilustración:
Consideremos las operaciones, Se refiere llave X con en el caché LRU: {1, 2, 3, 4, 1, 2, 5, 1, 2, 3}
Nota: Inicialmente no hay ninguna página en la memoria.Las imágenes a continuación muestran la ejecución paso a paso de las operaciones anteriores en el caché LRU.
Algoritmo:
- Cree una clase LRUCache con declarar una lista de tipo int, un mapa desordenado de tipo
- En la función de referencia de LRUCache
- Si este valor no está presente en la cola, coloque este valor delante de la cola y elimine el último valor si la cola está llena.
- Si el valor ya está presente, elimínelo de la cola y colóquelo al frente de la cola.
- En la función de visualización de impresión, LRUCache usa la cola comenzando desde el frente
A continuación se muestra la implementación del enfoque anterior:
C++
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;> > >// store references of key in cache> >unordered_map<>int>, list<>int>>::iterador>ma;> >int> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->número de página = número de página;> > >// Initialize prev and next as NULL> >temp->anterior = temporal->siguiente = NULL;> > >return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->contar = 0;> >queue->frente = cola->trasero = NULL;> > >// Number of frames that can be stored in memory> >queue->númeroDeMarcos = númeroDeMarcos;> > >return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->capacidad = capacidad;> > >// Create an array of pointers for referring queue nodes> >hash->matriz> >= (QNode**)>malloc>(hash->capacidad *>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->matriz[i] = NULO;> > >return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->contar == cola->numberOfFrames;> }> > // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->trasero == NULL;> }> > // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->frente == cola->trasero)> >queue->frente = NULO;> > >// Change rear and remove the previous rear> >QNode* temp = queue->trasero;> >queue->trasero = cola->trasero->anterior;> > >if> (queue->trasero)> >queue->trasero->siguiente = NULL;> > >free>(temp);> > >// decrement the number of full frames by 1> >queue->contar--;> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->matriz[cola->posterior->númerodepágina] = NULL;> >deQueue(queue);> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->siguiente = cola->frente;> > >// If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->trasero = cola->frente = temporal;> >else> // Else change the front> >{> >queue->frente->anterior = temp;> >queue->frente = temperatura;> >}> > >// Add page entry to hash also> >hash->matriz[númerodepágina] = temporal;> > >// increment number of full frames> >queue->contar++;> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->matriz [número de página];> > >// the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->frente) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->anterior->siguiente = reqPage->siguiente;> >if> (reqPage->siguiente)> >reqPage->siguiente->anterior = páginareq->anterior;> > >// If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->trasero) {> >queue->trasero = páginareq->anterior;> >queue->trasero->siguiente = NULL;> >}> > >// Put the requested page before current front> >reqPage->siguiente = cola->frente;> >reqPage->anterior = NULO;> > >// Change prev of current front> >reqPage->siguiente->anterior = reqPage;> > >// Change front to the requested page> >queue->frente = páginareq;> >}> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->frente->númerodepágina);> >printf>(>'%d '>, q->frente->siguiente->númerodepágina);> >printf>(>'%d '>, q->frente->siguiente->siguiente->númerodepágina);> >printf>(>'%d '>, q->frente->siguiente->siguiente->siguiente->númerodepágina);> > >return> 0;> }> |
arp - un comando
>
>
Java
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
tutorial de pyspark
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
C#
mapa vs conjunto
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>doble cola;> > >// store references of key in cache> >private> HashSet<>int>>hashSet;> > >// maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();> >hashSet =>new> HashSet<>int>>();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
JavaScript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
Implementación de caché LRU utilizando lista doblemente enlazada y hash :
La idea es muy básica, es decir, seguir insertando los elementos en la cabecera.
- Si el elemento no está presente en la lista, agréguelo al encabezado de la lista.
- si el elemento está presente en la lista, mueva el elemento al encabezado y mueva el elemento restante de la lista
Tenga en cuenta que la prioridad del nodo dependerá de la distancia de ese nodo a la cabeza, cuanto más cerca esté el nodo de la cabeza, mayor será la prioridad que tendrá. Entonces, cuando el tamaño de la caché está lleno y necesitamos eliminar algún elemento, eliminamos el elemento adyacente al final de la lista doblemente enlazada.
Implementación de caché LRU usando Deque y Hashmap:
La estructura de datos Deque permite la inserción y eliminación tanto desde el frente como desde el final, esta propiedad permite la implementación de LRU posible ya que el elemento frontal puede representar un elemento de alta prioridad, mientras que el elemento final puede ser el elemento de baja prioridad, es decir, el menos utilizado recientemente.
Laboral:
- Obtener operación : Comprueba si la clave existe en el mapa hash de la caché y sigue los siguientes casos en la deque:
- Si se encuentra la clave:
- El artículo se considera usado recientemente, por lo que se mueve al frente del deque.
- El valor asociado con la clave se devuelve como resultado de la
get>operación.- Si no se encuentra la clave:
- devuelve -1 para indicar que no existe dicha clave.
- Operación de puesta: Primero verifique si la clave ya existe en el mapa hash del caché y siga los siguientes casos en el deque
- Si la clave existe:
- Se actualiza el valor asociado a la clave.
- El elemento se mueve al frente del deque ya que ahora es el usado más recientemente.
- Si la clave no existe:
- Si el caché está lleno, significa que es necesario insertar un elemento nuevo y se debe desalojar el elemento utilizado menos recientemente. Esto se hace eliminando el elemento del final de la deque y la entrada correspondiente del mapa hash.
- Luego, el nuevo par clave-valor se inserta tanto en el mapa hash como en el frente del deque para indicar que es el elemento utilizado más recientemente.
Implementación de caché LRU usando Stack & Hashmap:
Implementar una caché LRU (menos recientemente utilizada) usando una estructura de datos de pila y hash puede ser un poco complicado porque una pila simple no proporciona acceso eficiente al elemento usado menos recientemente. Sin embargo, puedes combinar una pila con un mapa hash para lograr esto de manera eficiente. Aquí hay un enfoque de alto nivel para implementarlo:
- Utilice un mapa hash : El mapa hash almacenará los pares clave-valor del caché. Las claves se asignarán a los nodos correspondientes de la pila.
- Usa una pila : La pila mantendrá el orden de las claves según su uso. El elemento usado menos recientemente estará en la parte inferior de la pila y el elemento usado más recientemente estará en la parte superior.
Este enfoque no es tan eficiente y, por lo tanto, no se utiliza con frecuencia.
Caché LRU usando implementación de contador:
Cada bloque en el caché tendrá su propio contador LRU al que pertenece el valor del contador. {0 a n-1} , aquí ' norte 'representa el tamaño del caché. El bloque que se cambia durante el reemplazo del bloque se convierte en el bloque MRU y, como resultado, su valor de contador cambia a n – 1. Los valores de contador mayores que el valor del contador del bloque al que se accede se reducen en uno. Los bloques restantes permanecen inalterados.
| Valor de contra | Prioridad | Estado usado inttostr java |
|---|---|---|
| 0 | Bajo | Menos usado recientemente |
| n-1 | Alto | Usado más recientemente |
Implementación de caché LRU mediante actualizaciones diferidas:
La implementación de una caché LRU (menos utilizada recientemente) mediante actualizaciones diferidas es una técnica común para mejorar la eficiencia de las operaciones de la caché. Las actualizaciones diferidas implican realizar un seguimiento del orden en el que se accede a los elementos sin actualizar inmediatamente toda la estructura de datos. Cuando se produce una pérdida de caché, puede decidir si desea realizar o no una actualización completa según algunos criterios.
Análisis de complejidad de la caché LRU:
- Complejidad del tiempo:
- Operación Put(): O(1), es decir, el tiempo necesario para insertar o actualizar un nuevo par clave-valor es constante
- Operación Get(): O(1), es decir, el tiempo necesario para obtener el valor de una clave es constante
- Espacio Auxiliar: O(N) donde N es la capacidad de la caché.
Ventajas del caché LRU:
- Acceso Rápido : Se necesita O(1) tiempo para acceder a los datos desde la caché LRU.
- Actualización rápida : Se necesita O(1) tiempo para actualizar un par clave-valor en la caché LRU.
- Eliminación rápida de los datos utilizados menos recientemente : Se necesita O(1) para eliminar aquello que no se ha utilizado recientemente.
- Sin golpes: LRU es menos susceptible a la paliza en comparación con FIFO porque considera el historial de uso de las páginas. Puede detectar qué páginas se utilizan con frecuencia y priorizarlas para la asignación de memoria, lo que reduce la cantidad de errores de página y operaciones de E/S de disco.
Desventajas del caché LRU:
- Requiere un tamaño de caché grande para aumentar la eficiencia.
- Requiere la implementación de una estructura de datos adicional.
- La asistencia de hardware es alta.
- En LRU la detección de errores es difícil en comparación con otros algoritmos.
- Tiene una aceptabilidad limitada.
Aplicación del mundo real de LRU Cache:
- En sistemas de bases de datos para obtener resultados de consultas rápidos.
- En Sistemas Operativos para minimizar fallos de página.
- Editores de texto e IDE para almacenar archivos o fragmentos de código de uso frecuente
- Los enrutadores y conmutadores de red utilizan LRU para aumentar la eficiencia de la red informática
- En optimizaciones del compilador
- Herramientas de predicción de texto y autocompletado