Como sabemos, el algoritmo de aprendizaje automático supervisado se puede clasificar en términos generales en algoritmos de regresión y clasificación. En los algoritmos de regresión, hemos predicho la salida de valores continuos, pero para predecir los valores categóricos, necesitamos algoritmos de clasificación.
¿Qué es el algoritmo de clasificación?
El algoritmo de clasificación es una técnica de aprendizaje supervisado que se utiliza para identificar la categoría de nuevas observaciones sobre la base de datos de entrenamiento. En Clasificación, un programa aprende del conjunto de datos u observaciones dados y luego clasifica las nuevas observaciones en varias clases o grupos. Como, Sí o No, 0 o 1, Spam o No Spam, perro o gato, etc. Las clases se pueden llamar objetivos/etiquetas o categorías.
tutorial javafx
A diferencia de la regresión, la variable de salida de Clasificación es una categoría, no un valor, como 'Verde o Azul', 'fruta o animal', etc. Dado que el algoritmo de Clasificación es una técnica de aprendizaje supervisado, toma datos de entrada etiquetados, que significa que contiene entrada con la salida correspondiente.
En el algoritmo de clasificación, una función de salida discreta (y) se asigna a la variable de entrada (x).
y=f(x), where y = categorical output
El mejor ejemplo de un algoritmo de clasificación ML es Detector de spam de correo electrónico .
El objetivo principal del algoritmo de clasificación es identificar la categoría de un conjunto de datos determinado, y estos algoritmos se utilizan principalmente para predecir la salida de los datos categóricos.
Los algoritmos de clasificación se pueden comprender mejor utilizando el siguiente diagrama. En el siguiente diagrama, hay dos clases, clase A y clase B. Estas clases tienen características similares entre sí y diferentes a otras clases.
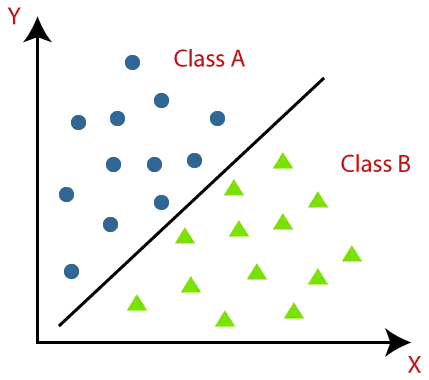
El algoritmo que implementa la clasificación de un conjunto de datos se conoce como clasificador. Hay dos tipos de Clasificaciones:
Ejemplos: SÍ o NO, MASCULINO o HEMBRA, SPAM o NO SPAM, GATO o PERRO, etc.
Ejemplo: Clasificaciones de tipos de cultivos, Clasificación de tipos de música.
Estudiantes en problemas de clasificación:
En los problemas de clasificación, hay dos tipos de alumnos:
aprendizaje automático y tipos
Ejemplo: Algoritmo K-NN, razonamiento basado en casos
Tipos de algoritmos de clasificación de ML:
Los algoritmos de clasificación se pueden dividir a su vez en dos categorías principales:
- Regresión logística
- Máquinas de vectores de soporte
- K-vecinos más cercanos
- SVM del núcleo
- Na�ve Bayes
- Clasificación del árbol de decisión
- Clasificación aleatoria de bosques
Nota: Aprenderemos los algoritmos anteriores en capítulos posteriores.
Evaluación de un modelo de clasificación:
Una vez completado nuestro modelo, es necesario evaluar su desempeño; o es un modelo de clasificación o de regresión. Entonces, para evaluar un modelo de Clasificación, tenemos las siguientes formas:
1. Pérdida de registro o pérdida de entropía cruzada:
- Se utiliza para evaluar el rendimiento de un clasificador, cuya salida es un valor de probabilidad entre 0 y 1.
- Para un buen modelo de clasificación binaria, el valor de pérdida logarítmica debe ser cercano a 0.
- El valor de la pérdida logarítmica aumenta si el valor previsto se desvía del valor real.
- La menor pérdida logarítmica representa la mayor precisión del modelo.
- Para la clasificación binaria, la entropía cruzada se puede calcular como:
?(ylog(p)+(1?y)log(1?p))
Donde y= producción real, p= producción prevista.
2. Matriz de confusión:
- La matriz de confusión nos proporciona una matriz/tabla como resultado y describe el rendimiento del modelo.
- También se la conoce como matriz de error.
- La matriz consta de predicciones resultantes en forma resumida, que tiene un número total de predicciones correctas y predicciones incorrectas. La matriz se parece a la siguiente tabla:
| Positivo real | Negativo real | |
|---|---|---|
| Positivo previsto | Verdadero positivo | Falso positivo |
| Negativo previsto | Falso negativo | Verdadero Negativo |

3. Curva AUC-ROC:
- La curva ROC significa Curva de características operativas del receptor y AUC significa Área bajo la curva .
- Es un gráfico que muestra el desempeño del modelo de clasificación en diferentes umbrales.
- Para visualizar el rendimiento del modelo de clasificación multiclase, utilizamos la curva AUC-ROC.
- La curva ROC se traza con TPR y FPR, donde TPR (tasa de verdaderos positivos) en el eje Y y FPR (tasa de falsos positivos) en el eje X.
Casos de uso de algoritmos de clasificación
Los algoritmos de clasificación se pueden utilizar en diferentes lugares. A continuación se muestran algunos casos de uso populares de algoritmos de clasificación:
- Detección de spam de correo electrónico
- Reconocimiento de voz
- Identificaciones de células tumorales cancerosas.
- Clasificación de drogas
- Identificación biométrica, etc.