El aprendizaje automático es la rama de Inteligencia artificial que se centra en desarrollar modelos y algoritmos que permitan a las computadoras aprender de los datos y mejorar a partir de experiencias previas sin estar programadas explícitamente para cada tarea. En palabras simples, ML enseña a los sistemas a pensar y comprender como humanos aprendiendo de los datos.
En este artículo exploraremos los distintos tipos de algoritmos de aprendizaje automático que son importantes para necesidades futuras. Aprendizaje automático Generalmente es un sistema de capacitación para aprender de experiencias pasadas y mejorar el desempeño con el tiempo. Aprendizaje automático ayuda a predecir cantidades masivas de datos. Ayuda a ofrecer resultados rápidos y precisos para obtener oportunidades rentables.
java obtener fecha actual
Tipos de aprendizaje automático
Existen varios tipos de aprendizaje automático, cada uno con características y aplicaciones especiales. Algunos de los principales tipos de algoritmos de aprendizaje automático son los siguientes:
- Aprendizaje automático supervisado
- Aprendizaje automático no supervisado
- Aprendizaje automático semisupervisado
- Aprendizaje reforzado
Tipos de aprendizaje automático
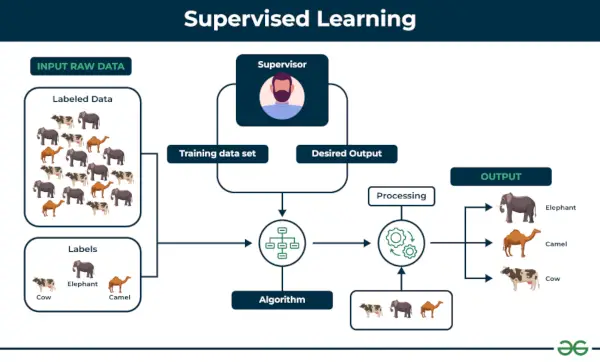
1. Aprendizaje automático supervisado
Aprendizaje supervisado se define como cuando un modelo se entrena en un Conjunto de datos etiquetados . Los conjuntos de datos etiquetados tienen parámetros de entrada y salida. En Aprendizaje supervisado Los algoritmos aprenden a mapear puntos entre entradas y salidas correctas. Tiene conjuntos de datos de entrenamiento y validación etiquetados.
Aprendizaje supervisado
Entendámoslo con la ayuda de un ejemplo.
Ejemplo: Considere un escenario en el que tiene que crear un clasificador de imágenes para diferenciar entre perros y gatos. Si alimenta los conjuntos de datos de perros y gatos con imágenes etiquetadas al algoritmo, la máquina aprenderá a clasificar entre un perro y un gato a partir de estas imágenes etiquetadas. Cuando ingresamos nuevas imágenes de perros o gatos que nunca antes había visto, utilizará los algoritmos aprendidos y predecirá si es un perro o un gato. Así es como aprendizaje supervisado funciona, y esto es particularmente una clasificación de imágenes.
Hay dos categorías principales de aprendizaje supervisado que se mencionan a continuación:
- Clasificación
- Regresión
Clasificación
Clasificación se ocupa de predecir categórico variables de destino, que representan clases o etiquetas discretas. Por ejemplo, clasificar los correos electrónicos como spam o no, o predecir si un paciente tiene un alto riesgo de sufrir una enfermedad cardíaca. Los algoritmos de clasificación aprenden a asignar las características de entrada a una de las clases predefinidas.
Aquí hay algunos algoritmos de clasificación:
- Regresión logística
- Máquinas de vectores soporte
- Bosque aleatorio
- Árbol de decisión
- K-Vecinos más cercanos (KNN)
- Bayes ingenuo
Regresión
Regresión , por otro lado, se ocupa de predecir continuo variables objetivo, que representan valores numéricos. Por ejemplo, predecir el precio de una casa en función de su tamaño, ubicación y comodidades, o pronosticar las ventas de un producto. Los algoritmos de regresión aprenden a asignar las características de entrada a un valor numérico continuo.
Aquí hay algunos algoritmos de regresión:
- Regresión lineal
- Regresión polinomial
- Regresión de cresta
- Regresión de lazo
- Árbol de decisión
- Bosque aleatorio
Ventajas del aprendizaje automático supervisado
- Aprendizaje supervisado Los modelos pueden tener una alta precisión ya que están entrenados en datos etiquetados .
- El proceso de toma de decisiones en los modelos de aprendizaje supervisado suele ser interpretable.
- A menudo se puede utilizar en modelos previamente entrenados, lo que ahorra tiempo y recursos al desarrollar nuevos modelos desde cero.
Desventajas del aprendizaje automático supervisado
- Tiene limitaciones para conocer patrones y puede tener problemas con patrones invisibles o inesperados que no están presentes en los datos de entrenamiento.
- Puede llevar mucho tiempo y ser costoso, ya que depende de etiquetado solo datos.
- Puede dar lugar a generalizaciones deficientes basadas en nuevos datos.
Aplicaciones del aprendizaje supervisado
El aprendizaje supervisado se utiliza en una amplia variedad de aplicaciones, que incluyen:
- Clasificación de imágenes : Identifique objetos, rostros y otras características en imágenes.
- Procesamiento natural del lenguaje: Extraiga información del texto, como opiniones, entidades y relaciones.
- Reconocimiento de voz : convierte el lenguaje hablado en texto.
- Sistemas de recomendación : Realizar recomendaciones personalizadas a los usuarios.
- Análisis predictivo : Prediga resultados, como ventas, pérdida de clientes y precios de acciones.
- Diagnostico medico : Detectar enfermedades y otras condiciones médicas.
- Detección de fraude : Identificar transacciones fraudulentas.
- Vehículos autónomos : Reconocer y responder a objetos del entorno.
- Detección de spam de correo electrónico : Clasifica los correos electrónicos como spam o no spam.
- Control de calidad en la fabricación. : Inspeccionar los productos en busca de defectos.
- Puntuacion de credito : Evaluar el riesgo de que un prestatario incumpla un préstamo.
- Juego de azar : Reconoce personajes, analiza el comportamiento del jugador y crea NPC.
- Atención al cliente : Automatiza las tareas de atención al cliente.
- Predicción del tiempo : Haga predicciones de temperatura, precipitación y otros parámetros meteorológicos.
- Analítica deportiva : Analice el rendimiento de los jugadores, haga predicciones de juegos y optimice estrategias.
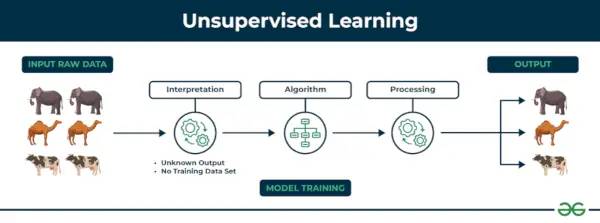
2. Aprendizaje automático no supervisado
Aprendizaje sin supervisión El aprendizaje no supervisado es un tipo de técnica de aprendizaje automático en la que un algoritmo descubre patrones y relaciones utilizando datos sin etiquetar. A diferencia del aprendizaje supervisado, el aprendizaje no supervisado no implica proporcionar al algoritmo resultados objetivo etiquetados. El objetivo principal del aprendizaje no supervisado suele ser descubrir patrones, similitudes o grupos ocultos dentro de los datos, que luego pueden usarse para diversos fines, como exploración de datos, visualización, reducción de dimensionalidad y más.
mb en gb
Aprendizaje sin supervisión
Entendámoslo con la ayuda de un ejemplo.
Ejemplo: Considere que tiene un conjunto de datos que contiene información sobre las compras que realizó en la tienda. Mediante la agrupación, el algoritmo puede agrupar el mismo comportamiento de compra entre usted y otros clientes, lo que revela clientes potenciales sin etiquetas predefinidas. Este tipo de información puede ayudar a las empresas a conseguir clientes objetivo, así como a identificar valores atípicos.
Hay dos categorías principales de aprendizaje no supervisado que se mencionan a continuación:
- Agrupación
- Asociación
Agrupación
Agrupación Es el proceso de agrupar puntos de datos en grupos en función de su similitud. Esta técnica es útil para identificar patrones y relaciones en datos sin la necesidad de ejemplos etiquetados.
A continuación se muestran algunos algoritmos de agrupación:
- Algoritmo de agrupación de K-medias
- Algoritmo de cambio medio
- Algoritmo DBSCAN
- Análisis de componentes principales
- Análisis de componentes independientes
Asociación
Aprender la regla de asociación ing es una técnica para descubrir relaciones entre elementos de un conjunto de datos. Identifica reglas que indican que la presencia de un elemento implica la presencia de otro elemento con una probabilidad específica.
A continuación se muestran algunos algoritmos de aprendizaje de reglas de asociación:
- Algoritmo a priori
- Brillo
- Algoritmo de crecimiento de FP
Ventajas del aprendizaje automático no supervisado
- Ayuda a descubrir patrones ocultos y diversas relaciones entre los datos.
- Se utiliza para tareas como segmentación de clientes, detección de anomalías, y exploración de datos .
- No requiere datos etiquetados y reduce el esfuerzo de etiquetar datos.
Desventajas del aprendizaje automático no supervisado
- Sin utilizar etiquetas, puede resultar difícil predecir la calidad del resultado del modelo.
- La interpretabilidad del grupo puede no ser clara y puede no tener interpretaciones significativas.
- Tiene técnicas como codificadores automáticos y reducción de dimensionalidad que se puede utilizar para extraer características significativas de los datos sin procesar.
Aplicaciones del aprendizaje no supervisado
A continuación se muestran algunas aplicaciones comunes del aprendizaje no supervisado:
- Agrupación : Agrupe puntos de datos similares en grupos.
- Detección de anomalías : Identifique valores atípicos o anomalías en los datos.
- Reducción de dimensionalidad : Reducir la dimensionalidad de los datos preservando su información esencial.
- Sistemas de recomendación : Sugiera productos, películas o contenido a los usuarios según su comportamiento histórico o sus preferencias.
- Modelado de temas : Descubra temas latentes dentro de una colección de documentos.
- Estimación de densidad : Estimar la función de densidad de probabilidad de los datos.
- Compresión de imágenes y vídeos. : Reduzca la cantidad de almacenamiento requerido para contenido multimedia.
- Preprocesamiento de datos : Ayuda con tareas de preprocesamiento de datos, como limpieza de datos, imputación de valores faltantes y escalado de datos.
- Análisis de la cesta de la compra : Descubra asociaciones entre productos.
- Análisis de datos genómicos. : Identificar patrones o agrupar genes con perfiles de expresión similares.
- Segmentación de imagen : Segmente imágenes en regiones significativas.
- Detección de comunidad en redes sociales : Identificar comunidades o grupos de personas con intereses o conexiones similares.
- Análisis del comportamiento del cliente. : Descubra patrones e ideas para mejorar el marketing y las recomendaciones de productos.
- Recomendación de contenido : clasifique y etiquete contenido para que sea más fácil recomendar artículos similares a los usuarios.
- Análisis de datos exploratorios (EDA) : Explore datos y obtenga información antes de definir tareas específicas.
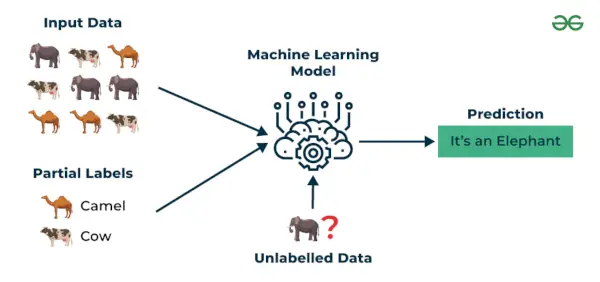
3. Aprendizaje semisupervisado
Aprendizaje semisupervisado es un algoritmo de aprendizaje automático que funciona entre supervisado y no supervisado aprendiendo por lo que usa ambos etiquetado y sin etiquetar datos. Es particularmente útil cuando obtener datos etiquetados es costoso, requiere mucho tiempo o recursos. Este enfoque es útil cuando el conjunto de datos es costoso y requiere mucho tiempo. Se elige el aprendizaje semisupervisado cuando los datos etiquetados requieren habilidades y recursos relevantes para poder entrenar o aprender de ellos.
Usamos estas técnicas cuando tratamos con datos que están un poco etiquetados y el resto en gran parte no está etiquetado. Podemos utilizar técnicas no supervisadas para predecir etiquetas y luego alimentar estas etiquetas a las técnicas supervisadas. Esta técnica es aplicable principalmente en el caso de conjuntos de datos de imágenes donde normalmente no todas las imágenes están etiquetadas.
Aprendizaje semisupervisado
Entendámoslo con la ayuda de un ejemplo.
Ejemplo : Considere que estamos creando un modelo de traducción de idiomas; tener traducciones etiquetadas para cada par de oraciones puede consumir muchos recursos. Permite que los modelos aprendan de pares de oraciones etiquetadas y no etiquetadas, lo que las hace más precisas. Esta técnica ha dado lugar a mejoras significativas en la calidad de los servicios de traducción automática.
Tipos de métodos de aprendizaje semisupervisados
Existen varios métodos diferentes de aprendizaje semisupervisado, cada uno con sus propias características. Algunos de los más comunes incluyen:
- Aprendizaje semisupervisado basado en gráficos: Este enfoque utiliza un gráfico para representar las relaciones entre los puntos de datos. Luego, el gráfico se utiliza para propagar etiquetas desde los puntos de datos etiquetados hasta los puntos de datos no etiquetados.
- Propagación de etiquetas: Este enfoque propaga de forma iterativa etiquetas desde los puntos de datos etiquetados a los puntos de datos sin etiquetar, en función de las similitudes entre los puntos de datos.
- Co-entrenamiento: Este enfoque entrena dos modelos diferentes de aprendizaje automático en diferentes subconjuntos de datos sin etiquetar. Luego, los dos modelos se utilizan para etiquetar las predicciones de cada uno.
- Auto-entrenamiento: Este enfoque entrena un modelo de aprendizaje automático con los datos etiquetados y luego utiliza el modelo para predecir etiquetas para los datos sin etiquetar. Luego, el modelo se vuelve a entrenar con los datos etiquetados y las etiquetas predichas para los datos sin etiquetar.
- Redes generativas adversarias (GAN) : Las GAN son un tipo de algoritmo de aprendizaje profundo que se puede utilizar para generar datos sintéticos. Las GAN se pueden utilizar para generar datos sin etiquetar para el aprendizaje semisupervisado entrenando dos redes neuronales, un generador y un discriminador.
Ventajas del aprendizaje automático semisupervisado
- Conduce a una mejor generalización en comparación con aprendizaje supervisado, ya que requiere datos tanto etiquetados como no etiquetados.
- Se puede aplicar a una amplia gama de datos.
Desventajas del aprendizaje automático semisupervisado
- Semi-supervisado Los métodos pueden ser más complejos de implementar en comparación con otros enfoques.
- Todavía requiere algo datos etiquetados que puede que no siempre estén disponibles o no sean fáciles de obtener.
- Los datos sin etiquetar pueden afectar el rendimiento del modelo en consecuencia.
Aplicaciones del aprendizaje semisupervisado
A continuación se muestran algunas aplicaciones comunes del aprendizaje semisupervisado:
- Clasificación de imágenes y reconocimiento de objetos : mejore la precisión de los modelos combinando un pequeño conjunto de imágenes etiquetadas con un conjunto más grande de imágenes sin etiquetar.
- Procesamiento del lenguaje natural (PNL) : mejore el rendimiento de los clasificadores y modelos de lenguaje combinando un pequeño conjunto de datos de texto etiquetados con una gran cantidad de texto sin etiquetar.
- Reconocimiento de voz: Mejore la precisión del reconocimiento de voz aprovechando una cantidad limitada de datos de voz transcritos y un conjunto más extenso de audio sin etiquetar.
- Sistemas de recomendación : Mejore la precisión de las recomendaciones personalizadas complementando un conjunto disperso de interacciones entre usuarios y elementos (datos etiquetados) con una gran cantidad de datos de comportamiento del usuario sin etiquetar.
- Atención sanitaria e imágenes médicas : Mejore el análisis de imágenes médicas utilizando un pequeño conjunto de imágenes médicas etiquetadas junto con un conjunto más grande de imágenes sin etiquetar.
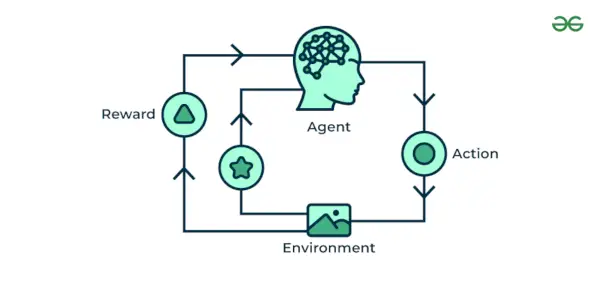
4. Aprendizaje automático de refuerzo
Aprendizaje automático de refuerzo Un algoritmo es un método de aprendizaje que interactúa con el entorno produciendo acciones y descubriendo errores. Prueba, error y retraso son las características más relevantes del aprendizaje por refuerzo. En esta técnica, el modelo sigue aumentando su rendimiento utilizando Reward Feedback para aprender el comportamiento o patrón. Estos algoritmos son específicos de un problema particular, p. Coche autónomo de Google, AlphaGo, donde un robot compite con los humanos e incluso con él mismo para obtener cada vez mejores resultados en Go Game. Cada vez que alimentamos datos, ellos aprenden y agregan los datos a su conocimiento, que son datos de entrenamiento. Por lo tanto, cuanto más aprende, mejor se capacita y, por tanto, se adquiere experiencia.
Estos son algunos de los algoritmos de aprendizaje por refuerzo más comunes:
desactivar el modo desarrollador android
- Q-aprendizaje: Q-learning es un algoritmo RL sin modelo que aprende una función Q, que asigna estados a acciones. La función Q estima la recompensa esperada por realizar una acción particular en un estado determinado.
- SARSA (Estado-Acción-Recompensa-Estado-Acción): SARSA es otro algoritmo RL sin modelo que aprende una función Q. Sin embargo, a diferencia del Q-learning, SARSA actualiza la función Q para la acción que realmente se tomó, en lugar de la acción óptima.
- Q-aprendizaje profundo : Deep Q-learning es una combinación de Q-learning y aprendizaje profundo. Deep Q-learning utiliza una red neuronal para representar la función Q, lo que le permite aprender relaciones complejas entre estados y acciones.
Aprendizaje automático de refuerzo
Entendámoslo con la ayuda de ejemplos.
Ejemplo: Considere que está entrenando a un AI agente para jugar un juego como el ajedrez. El agente explora diferentes movimientos y recibe comentarios positivos o negativos según el resultado. El aprendizaje por refuerzo también encuentra aplicaciones en las que aprenden a realizar tareas interactuando con su entorno.
Tipos de aprendizaje automático por refuerzo
Hay dos tipos principales de aprendizaje por refuerzo:
Refuerzo positivo
- Recompensa al agente por realizar una acción deseada.
- Alienta al agente a repetir el comportamiento.
- Ejemplos: Darle una golosina a un perro por sentarse, otorgar un punto en un juego por una respuesta correcta.
Reforzamiento negativo
- Elimina un estímulo indeseable para fomentar una conducta deseada.
- Disuade al agente de repetir la conducta.
- Ejemplos: apagar un timbre fuerte cuando se presiona una palanca, evitar una penalización al completar una tarea.
Ventajas del aprendizaje automático por refuerzo
- Tiene una toma de decisiones autónoma que se adapta bien a las tareas y que puede aprender a tomar una secuencia de decisiones, como la robótica y los juegos.
- Se prefiere esta técnica para lograr resultados a largo plazo que son muy difíciles de lograr.
- Se utiliza para resolver problemas complejos que no pueden resolverse mediante técnicas convencionales.
Desventajas del aprendizaje automático por refuerzo
- La formación de agentes de aprendizaje por refuerzo puede resultar costosa desde el punto de vista computacional y consumir mucho tiempo.
- El aprendizaje por refuerzo no es preferible a la resolución de problemas simples.
- Necesita muchos datos y muchos cálculos, lo que lo hace poco práctico y costoso.
Aplicaciones del aprendizaje automático por refuerzo
A continuación se muestran algunas aplicaciones del aprendizaje por refuerzo:
- Jugando juego : RL puede enseñar a los agentes a jugar juegos, incluso los complejos.
- Robótica : RL puede enseñar a los robots a realizar tareas de forma autónoma.
- Vehículos Autónomos : RL puede ayudar a los vehículos autónomos a navegar y tomar decisiones.
- Sistemas de recomendación : RL puede mejorar los algoritmos de recomendación al conocer las preferencias del usuario.
- Cuidado de la salud : RL se puede utilizar para optimizar los planes de tratamiento y el descubrimiento de fármacos.
- Procesamiento del lenguaje natural (PNL) : RL se puede utilizar en sistemas de diálogo y chatbots.
- Finanzas y Comercio : RL se puede utilizar para el comercio algorítmico.
- Gestión de inventario y cadena de suministro : RL se puede utilizar para optimizar las operaciones de la cadena de suministro.
- Gestión Energética : RL se puede utilizar para optimizar el consumo de energía.
- juegos de IA : RL se puede utilizar para crear NPC más inteligentes y adaptables en videojuegos.
- Asistentes personales adaptativos : RL se puede utilizar para mejorar los asistentes personales.
- Realidad Virtual (VR) y Realidad Aumentada (AR): RL se puede utilizar para crear experiencias inmersivas e interactivas.
- Controles Industriales : RL se puede utilizar para optimizar procesos industriales.
- Educación : RL se puede utilizar para crear sistemas de aprendizaje adaptativo.
- Agricultura : RL se puede utilizar para optimizar las operaciones agrícolas.
Debes consultar nuestro artículo detallado sobre : Algoritmos de aprendizaje automático
Conclusión
En conclusión, cada tipo de aprendizaje automático tiene su propio propósito y contribuye al papel general en el desarrollo de capacidades mejoradas de predicción de datos, y tiene el potencial de cambiar varias industrias como Ciencia de los datos . Ayuda a lidiar con la producción masiva de datos y la gestión de conjuntos de datos.
Tipos de aprendizaje automático: preguntas frecuentes
1. ¿Cuáles son los desafíos que enfrenta el aprendizaje supervisado?
Algunos de los desafíos que enfrenta el aprendizaje supervisado incluyen principalmente abordar los desequilibrios de clases, datos etiquetados de alta calidad y evitar el sobreajuste cuando los modelos funcionan mal con datos en tiempo real.
diferencia entre zorro y lobo
2. ¿Dónde podemos aplicar el aprendizaje supervisado?
El aprendizaje supervisado se utiliza comúnmente para tareas como analizar correos electrónicos no deseados, reconocimiento de imágenes y análisis de opiniones.
3. ¿Cómo es el futuro del aprendizaje automático?
El aprendizaje automático como perspectiva futura puede funcionar en áreas como el análisis meteorológico o climático, los sistemas sanitarios y la modelización autónoma.
4. ¿Cuáles son los diferentes tipos de aprendizaje automático?
Hay tres tipos principales de aprendizaje automático:
- Aprendizaje supervisado
- Aprendizaje sin supervisión
- Aprendizaje reforzado
5. ¿Cuáles son los algoritmos de aprendizaje automático más comunes?
Algunos de los algoritmos de aprendizaje automático más comunes incluyen:
- Regresión lineal
- Regresión logística
- Máquinas de vectores de soporte (SVM)
- K-vecinos más cercanos (KNN)
- Árboles de decisión
- Bosques aleatorios
- Redes neuronales artificiales