Los algoritmos de regresión y clasificación son algoritmos de aprendizaje supervisado. Ambos algoritmos se utilizan para la predicción en aprendizaje automático y funcionan con conjuntos de datos etiquetados. Pero la diferencia entre ambos es cómo se utilizan para diferentes problemas de aprendizaje automático.
La principal diferencia entre los algoritmos de regresión y clasificación para los que se utilizan los algoritmos de regresión predecir el continuo valores como precio, salario, edad, etc. y se utilizan algoritmos de clasificación para predecir/clasificar los valores discretos como Hombre o Mujer, Verdadero o Falso, Spam o No Spam, etc.
Considere el siguiente diagrama:
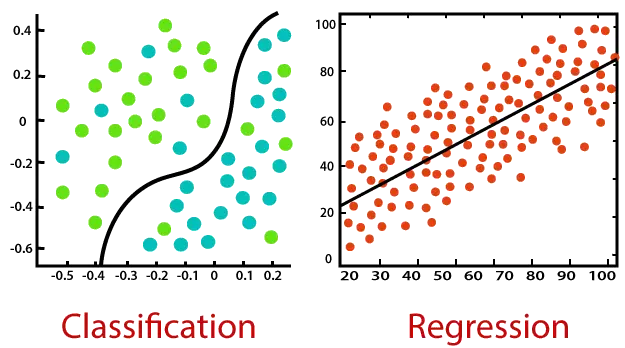
Clasificación:
La clasificación es un proceso de encontrar una función que ayude a dividir el conjunto de datos en clases según diferentes parámetros. En Clasificación, se entrena un programa de computadora en el conjunto de datos de entrenamiento y, en función de ese entrenamiento, clasifica los datos en diferentes clases.
La tarea del algoritmo de clasificación es encontrar la función de mapeo para mapear la entrada (x) a la salida discreta (y).
Ejemplo: El mejor ejemplo para comprender el problema de clasificación es la detección de spam en correo electrónico. El modelo se entrena sobre la base de millones de correos electrónicos con diferentes parámetros y cada vez que recibe un nuevo correo electrónico, identifica si el correo electrónico es spam o no. Si el correo electrónico es spam, se mueve a la carpeta Spam.
programa de matriz bidimensional en c
Tipos de algoritmos de clasificación de ML:
Los algoritmos de clasificación se pueden dividir en los siguientes tipos:
- Regresión logística
- K-vecinos más cercanos
- Máquinas de vectores de soporte
- SVM del núcleo
- Na�ve Bayes
- Clasificación del árbol de decisión
- Clasificación aleatoria de bosques
Regresión:
La regresión es un proceso de encontrar correlaciones entre variables dependientes e independientes. Ayuda a predecir las variables continuas, como la predicción de Las tendencias del mercado , predicción de precios de la vivienda, etc.
La tarea del algoritmo de regresión es encontrar la función de mapeo para mapear la variable de entrada (x) a la variable de salida continua (y).
Ejemplo: Supongamos que queremos hacer un pronóstico del tiempo, para ello usaremos el algoritmo de regresión. En la predicción del tiempo, el modelo se entrena con datos pasados y, una vez que se completa el entrenamiento, puede predecir fácilmente el tiempo para días futuros.
Tipos de algoritmo de regresión:
regexp_like en mysql
- Regresión lineal simple
- Regresión lineal múltiple
- Regresión polinomial
- Regresión de vectores de soporte
- Regresión del árbol de decisión
- Regresión forestal aleatoria
Diferencia entre regresión y clasificación
| Algoritmo de regresión | Algoritmo de clasificación |
|---|---|
| En Regresión, la variable de salida debe ser de naturaleza continua o valor real. | En Clasificación, la variable de salida debe ser un valor discreto. |
| La tarea del algoritmo de regresión es mapear el valor de entrada (x) con la variable de salida continua (y). | La tarea del algoritmo de clasificación es mapear el valor de entrada (x) con la variable de salida discreta (y). |
| Los algoritmos de regresión se utilizan con datos continuos. | Los algoritmos de clasificación se utilizan con datos discretos. |
| En Regresión, intentamos encontrar la línea de mejor ajuste, que pueda predecir el resultado con mayor precisión. | En Clasificación, intentamos encontrar el límite de decisión, que puede dividir el conjunto de datos en diferentes clases. |
| Los algoritmos de regresión se pueden utilizar para resolver problemas de regresión, como la predicción del tiempo, la predicción del precio de la vivienda, etc. | Los algoritmos de clasificación se pueden utilizar para resolver problemas de clasificación, como la identificación de correos electrónicos no deseados, el reconocimiento de voz, la identificación de células cancerosas, etc. |
| El algoritmo de regresión se puede dividir en regresión lineal y no lineal. | Los algoritmos de clasificación se pueden dividir en clasificador binario y clasificador multiclase. |