El comando uniq de Linux se utiliza para eliminar todas las líneas repetidas de un archivo. Además, se puede utilizar para mostrar el recuento de cualquier palabra, solo líneas repetidas, ignorar caracteres y comparar campos específicos. Es uno de los comandos más utilizados en el linux sistema. A menudo se utiliza con el ordenar comando porque compara personajes adyacentes. Descarta todas las líneas idénticas y escribe el resultado.
Sintaxis:
uniq [OPTION]... [INPUT [OUTPUT]]
Opciones:
Algunas opciones útiles de la línea de comando del comando uniq son las siguientes:
-c, --cuenta: antepone las líneas por el número de apariciones.
java final
-d, --repetido: se utiliza para imprimir líneas duplicadas, una para cada grupo.
-D: Se utiliza para imprimir todas las líneas duplicadas.
--todo repetido[=MÉTODO]: Es bastante similar a la opción '-D', la diferencia entre ambas opciones es que permite separar grupos con una línea vacía.
-f, --skip-fields=N: Se utiliza para evitar la comparación de los primeros N campos.
--grupo[=MÉTODO]: Se utiliza para mostrar todos los elementos y separa los grupos con una línea vacía.
-i, --ignorar-caso: Se utiliza para ignorar las diferencias al comparar.
-s, --skip-chars=N: Se utiliza para evitar la comparación de los primeros N caracteres.
tachado de rebajas
-u, --único: se utiliza para imprimir líneas únicas.
-z, --terminado en cero: Se utiliza para que el delimitador de línea sea NUL y no en modo de nueva línea.
-w, --check-chars=N: Se utiliza para comparar no más de N caracteres en líneas.
--ayuda: Se utiliza para mostrar documentación de ayuda.
juegos de mensajes en android
--versión: Se utiliza para mostrar la información de la versión.
Ejemplos de comando uniq
Veamos los siguientes ejemplos del comando uniq:
- Eliminar líneas repetidas
- contar el número de apariciones de una palabra
- Mostrar las líneas repetidas
- Mostrar las líneas únicas
- Ignorar personajes en comparación
- Ignorar campos en comparación
Eliminar líneas repetidas
Para eliminar líneas repetidas de un archivo, ejecute el comando básico uniq de la siguiente manera:
sort dupli.txt | uniq
El comando anterior eliminará las líneas duplicadas del archivo 'dupli.txt'. Considere el siguiente resultado:
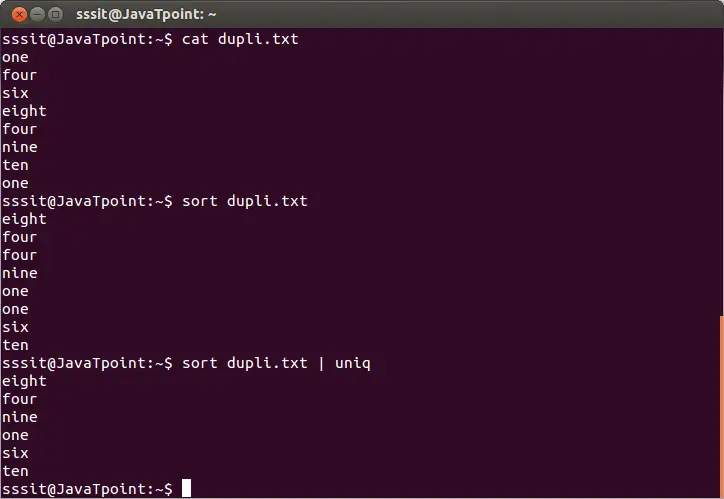
Del resultado anterior, las palabras repetidas se ignoran.
Contar el número de apariciones de una palabra.
Podemos contar el número de apariciones de una palabra usando el comando uniq. La opción '-c' se utiliza para contar la palabra. Ejecútelo de la siguiente manera:
si no, declaración java
sort dupli.txt | uniq -c
El comando anterior contará las palabras que vienen en 'dupli.txt'. Considere el siguiente resultado:

Del resultado anterior, el comando 'sort dupli.txt | uniq -c' cuenta el número de veces que se repite una palabra.
Mostrar las líneas repetidas
La opción '-d' se utiliza para mostrar solo las líneas repetidas. Solo mostrará las líneas que estarán más de una vez en un archivo y escribirá la salida en la salida estándar. Considere el siguiente comando:
sort dupli.txt | uniq -d
El comando anterior mostrará solo las líneas repetidas. Considere el siguiente resultado:

Mostrar las líneas únicas
La opción '-u' se utiliza para mostrar solo las líneas únicas (que no se repiten). Solo mostrará las líneas que ocurren una sola vez y escribirá el resultado en la salida estándar. Considere el siguiente comando:
sort dupli.txt | uniq -u
El comando anterior mostrará solo las líneas únicas del archivo 'dupli.txt'. Considere el siguiente resultado:
variable de bash

Ignorar personajes en comparación
La opción '-s' se utiliza para ignorar los caracteres en comparación. Ignorará el número especificado de caracteres y mostrará el resultado en la salida estándar. Considere el siguiente comando:
sort dupli.txt | uniq -s 2
El comando anterior ignorará los dos primeros caracteres en comparación con el archivo 'dupli.txt'. Considere el siguiente resultado:

Ignorar campos en comparación
La opción '-f' se utiliza para ignorar los campos. Considere el siguiente comando:
uniq -f 2 dupli2.txt
El comando anterior no comparará los dos primeros campos del archivo 'dupli2.txt'. Considere el siguiente resultado:

Del resultado anterior, se omiten los dos primeros campos y el resto de los campos se comparan desde el archivo 'dupli2.txt'.