Un proceso puede ser de dos tipos:
- Proceso independiente.
- Proceso cooperativo.
Un proceso independiente no se ve afectado por la ejecución de otros procesos, mientras que un proceso cooperativo puede verse afectado por otros procesos en ejecución. Aunque se puede pensar que esos procesos, que se ejecutan de forma independiente, se ejecutarán de manera muy eficiente, en realidad, hay muchas situaciones en las que se puede utilizar la naturaleza cooperativa para aumentar la velocidad, la conveniencia y la modularidad computacional. La comunicación entre procesos (IPC) es un mecanismo que permite que los procesos se comuniquen entre sí y sincronicen sus acciones. La comunicación entre estos procesos puede verse como un método de cooperación entre ellos. Los procesos pueden comunicarse entre sí a través de:
- Memoria compartida
- Paso de mensajes
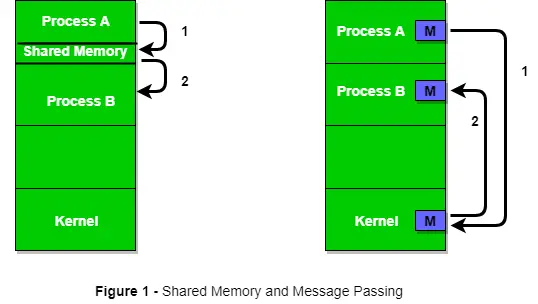
La Figura 1 a continuación muestra una estructura básica de comunicación entre procesos a través del método de memoria compartida y mediante el método de paso de mensajes.
Un sistema operativo puede implementar ambos métodos de comunicación. Primero, discutiremos los métodos de comunicación de memoria compartida y luego el paso de mensajes. La comunicación entre procesos que utilizan memoria compartida requiere que los procesos compartan alguna variable, y depende completamente de cómo la implementará el programador. Una forma de comunicación que utiliza la memoria compartida se puede imaginar así: supongamos que el proceso1 y el proceso2 se ejecutan simultáneamente y comparten algunos recursos o utilizan información de otro proceso. Process1 genera información sobre ciertos cálculos o recursos que se utilizan y la mantiene como un registro en la memoria compartida. Cuando el proceso2 necesite utilizar la información compartida, verificará el registro almacenado en la memoria compartida, tomará nota de la información generada por el proceso1 y actuará en consecuencia. Los procesos pueden utilizar la memoria compartida para extraer información como un registro de otro proceso, así como para entregar información específica a otros procesos.
Analicemos un ejemplo de comunicación entre procesos utilizando el método de memoria compartida.
i) Método de memoria compartida
Ej: problema productor-consumidor
Hay dos procesos: Productor y Consumidor. El productor produce algunos artículos y el consumidor consume esos artículos. Los dos procesos comparten un espacio común o ubicación de memoria conocida como buffer donde se almacena el artículo producido por el Productor y desde el cual el Consumidor consume el artículo si es necesario. Hay dos versiones de este problema: la primera se conoce como el problema del búfer ilimitado en el que el Productor puede seguir produciendo elementos y no hay límite en el tamaño del búfer, la segunda se conoce como el problema del búfer limitado en el cual el Productor puede producir hasta una cierta cantidad de artículos antes de comenzar a esperar a que el Consumidor los consuma. Discutiremos el problema del buffer acotado. Primero, el Productor y el Consumidor compartirán alguna memoria común, luego el productor comenzará a producir artículos. Si el artículo total producido es igual al tamaño del buffer, el productor esperará hasta que el consumidor lo consuma. Del mismo modo, el consumidor comprobará primero la disponibilidad del artículo. Si no hay ningún artículo disponible, el Consumidor esperará a que el Productor lo produzca. Si hay artículos disponibles, el Consumidor los consumirá. El pseudocódigo para demostrar se proporciona a continuación:
Datos compartidos entre los dos procesos
C
#define buff_max 25> #define mod %> >struct> item{> >// different member of the produced data> >// or consumed data> >---------> >}> > >// An array is needed for holding the items.> >// This is the shared place which will be> >// access by both process> >// item shared_buff [ buff_max ];> > >// Two variables which will keep track of> >// the indexes of the items produced by producer> >// and consumer The free index points to> >// the next free index. The full index points to> >// the first full index.> >int> free_index = 0;> >int> full_index = 0;> > |
>
>
Código de proceso del productor
C
item nextProduced;> > >while>(1){> > >// check if there is no space> >// for production.> >// if so keep waiting.> >while>((free_index+1) mod buff_max == full_index);> > >shared_buff[free_index] = nextProduced;> >free_index = (free_index + 1) mod buff_max;> >}> |
>
>
Código de proceso del consumidor
C
item nextConsumed;> > >while>(1){> > >// check if there is an available> >// item for consumption.> >// if not keep on waiting for> >// get them produced.> >while>((free_index == full_index);> > >nextConsumed = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >}> |
>
>
En el código anterior, el Productor comenzará a producir nuevamente cuando el mod buff max (free_index+1) sea gratuito porque si no es gratuito, esto implica que todavía hay elementos que el Consumidor puede consumir, por lo que no es necesario. para producir más. De manera similar, si el índice libre y el índice completo apuntan al mismo índice, esto implica que no hay artículos para consumir.
Implementación general de C++:
C++
#include> #include> #include> #include> #define buff_max 25> #define mod %> struct> item {> >// different member of the produced data> >// or consumed data> >// ---------> };> // An array is needed for holding the items.> // This is the shared place which will be> // access by both process> // item shared_buff[buff_max];> // Two variables which will keep track of> // the indexes of the items produced by producer> // and consumer The free index points to> // the next free index. The full index points to> // the first full index.> std::atomic<>int>>índice_libre(0);> std::atomic<>int>>índice_completo(0);> std::mutex mtx;> void> producer() {> >item new_item;> >while> (>true>) {> >// Produce the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >// Add the item to the buffer> >while> (((free_index + 1) mod buff_max) == full_index) {> >// Buffer is full, wait for consumer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Add the item to the buffer> >// shared_buff[free_index] = new_item;> >free_index = (free_index + 1) mod buff_max;> >mtx.unlock();> >}> }> void> consumer() {> >item consumed_item;> >while> (>true>) {> >while> (free_index == full_index) {> >// Buffer is empty, wait for producer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Consume the item from the buffer> >// consumed_item = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >mtx.unlock();> >// Consume the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> }> int> main() {> >// Create producer and consumer threads> >std::vectorthread>hilos; threads.emplace_back(productor); threads.emplace_back(consumidor); // Espera a que finalicen los hilos for (auto& thread : threads) { thread.join(); } devolver 0; }> |
>
>
es grasa proteica
Tenga en cuenta que la clase atómica se utiliza para garantizar que las variables compartidas free_index y full_index se actualicen atómicamente. El mutex se utiliza para proteger la sección crítica donde se accede al búfer compartido. La función sleep_for se utiliza para simular la producción y el consumo de artículos.
ii) Método de transferencia de mensajes
Ahora, comenzaremos nuestra discusión sobre la comunicación entre procesos mediante el paso de mensajes. En este método, los procesos se comunican entre sí sin utilizar ningún tipo de memoria compartida. Si dos procesos p1 y p2 quieren comunicarse entre sí, proceden de la siguiente manera:
- Establezca un enlace de comunicación (si ya existe un enlace, no es necesario volver a establecerlo).
- Empiece a intercambiar mensajes utilizando primitivas básicas.
Necesitamos al menos dos primitivas:
– enviar (mensaje, destino) o enviar (mensaje)
– recibir (mensaje, host) o recibir (mensaje)

El tamaño del mensaje puede ser de tamaño fijo o de tamaño variable. Si es de tamaño fijo, es fácil para un diseñador de SO pero complicado para un programador y si es de tamaño variable entonces es fácil para un programador pero complicado para el diseñador de SO. Un mensaje estándar puede tener dos partes: encabezado y cuerpo.
El parte del encabezado se utiliza para almacenar el tipo de mensaje, la identificación de destino, la identificación de origen, la longitud del mensaje y la información de control. La información de control contiene información como qué hacer si se queda sin espacio en el búfer, número de secuencia y prioridad. Generalmente, el mensaje se envía utilizando el estilo FIFO.
Mensaje que pasa a través del enlace de comunicación.
Enlace de comunicación directa e indirecta
Ahora comenzaremos nuestra discusión sobre los métodos para implementar enlaces de comunicación. Al implementar el enlace, hay algunas preguntas que deben tenerse en cuenta, como:
- ¿Cómo se establecen los vínculos?
- ¿Se puede asociar un enlace a más de dos procesos?
- ¿Cuántos vínculos puede haber entre cada par de procesos comunicantes?
- ¿Cuál es la capacidad de un enlace? ¿El tamaño de un mensaje que el enlace puede acomodar es fijo o variable?
- ¿Un enlace es unidireccional o bidireccional?
Un enlace tiene cierta capacidad que determina la cantidad de mensajes que pueden residir en él temporalmente para lo cual cada enlace tiene una cola asociada que puede ser de capacidad cero, capacidad limitada o capacidad ilimitada. En capacidad cero, el remitente espera hasta que el receptor le informa que ha recibido el mensaje. En casos de capacidad distinta de cero, un proceso no sabe si se ha recibido o no un mensaje después de la operación de envío. Para ello, el remitente debe comunicarse explícitamente con el receptor. La implementación del enlace depende de la situación, puede ser un enlace de comunicación directo o un enlace de comunicación indirecto.
Enlaces de comunicación directa Se implementan cuando los procesos utilizan un identificador de proceso específico para la comunicación, pero es difícil identificar al remitente con anticipación.
Por ejemplo el servidor de impresión.
Comunicación indirecta se realiza a través de un buzón de correo compartido (puerto), que consta de una cola de mensajes. El remitente guarda el mensaje en el buzón y el receptor lo recoge.
Mensaje pasando por el intercambio de mensajes.
Paso de mensajes sincrónico y asincrónico:
Un proceso bloqueado es aquel que está esperando algún evento, como que un recurso esté disponible o que se complete una operación de E/S. La IPC es posible entre los procesos en la misma computadora, así como en los procesos que se ejecutan en diferentes computadoras, es decir, en un sistema en red/distribuido. En ambos casos, el proceso puede bloquearse o no mientras se envía un mensaje o se intenta recibir un mensaje, por lo que el paso del mensaje puede ser bloqueante o no bloqueante. Se considera bloqueo sincrónico y bloqueo de envío significa que el remitente será bloqueado hasta que el receptor reciba el mensaje. Similarmente, bloqueo de recepción hace que el receptor se bloquee hasta que haya un mensaje disponible. Se considera no bloqueo asincrónico y el envío sin bloqueo hace que el remitente envíe el mensaje y continúe. De manera similar, la recepción sin bloqueo hace que el receptor reciba un mensaje válido o nulo. Después de un análisis cuidadoso, podemos llegar a la conclusión de que para un remitente es más natural no bloquear después de pasar el mensaje, ya que puede ser necesario enviar el mensaje a diferentes procesos. Sin embargo, el remitente espera un acuse de recibo del receptor en caso de que el envío falle. De manera similar, es más natural que un receptor se bloquee después de emitir la recepción, ya que la información del mensaje recibido puede usarse para una ejecución posterior. Al mismo tiempo, si el envío del mensaje sigue fallando, el receptor tendrá que esperar indefinidamente. Por eso también consideramos la otra posibilidad del paso de mensajes. Básicamente existen tres combinaciones preferidas:
- Bloquear envío y bloquear recepción
- Envío sin bloqueo y recepción sin bloqueo
- Envío sin bloqueo y recepción con bloqueo (más utilizado)
En mensaje directo pasando , El proceso que quiera comunicarse debe nombrar explícitamente al destinatario o remitente de la comunicación.
p.ej. enviar(p1, mensaje) significa enviar el mensaje a p1.
Similarmente, recibir(p2, mensaje) significa recibir el mensaje de p2.
En este método de comunicación, el enlace de comunicación se establece automáticamente, que puede ser unidireccional o bidireccional, pero se puede usar un enlace entre un par de remitente y receptor y un par de remitente y receptor no debe poseer más de un par de Enlaces. También se puede implementar la simetría y asimetría entre el envío y la recepción, es decir, ambos procesos se nombrarán entre sí para enviar y recibir los mensajes o solo el remitente nombrará al receptor para enviar el mensaje y no hay necesidad de que el receptor nombre al remitente para recibiendo el mensaje. El problema con este método de comunicación es que si cambia el nombre de un proceso, este método no funcionará.
En el paso de mensajes indirectos , los procesos utilizan buzones de correo (también conocidos como puertos) para enviar y recibir mensajes. Cada buzón tiene una identificación única y los procesos pueden comunicarse solo si comparten un buzón. Enlace establecido sólo si los procesos comparten un buzón común y un único enlace puede asociarse con muchos procesos. Cada par de procesos puede compartir varios enlaces de comunicación y estos enlaces pueden ser unidireccionales o bidireccionales. Supongamos que dos procesos quieren comunicarse mediante el paso indirecto de mensajes, las operaciones requeridas son: crear un buzón, usar este buzón para enviar y recibir mensajes y luego destruir el buzón. Las primitivas estándar utilizadas son: enviar un mensaje) lo que significa enviar el mensaje al buzón A. La primitiva para recibir el mensaje también funciona de la misma manera, p. recibido (A, mensaje) . Hay un problema con la implementación de este buzón. Supongamos que hay más de dos procesos compartiendo el mismo buzón y supongamos que el proceso p1 envía un mensaje al buzón, ¿cuál proceso será el receptor? Esto se puede resolver haciendo cumplir que solo dos procesos puedan compartir un único buzón o haciendo que solo un proceso pueda ejecutar la recepción en un momento dado o seleccionando cualquier proceso al azar y notificando al remitente sobre el receptor. Un buzón se puede hacer privado para un único par de remitente/receptor y también se puede compartir entre varios pares de remitente/receptor. El puerto es una implementación de dicho buzón que puede tener varios remitentes y un solo receptor. Se utiliza en aplicaciones cliente/servidor (en este caso el servidor es el receptor). El puerto es propiedad del proceso receptor y lo crea el sistema operativo a petición del proceso receptor y puede destruirse a petición del mismo procesador receptor cuando el receptor finaliza. Se puede hacer cumplir que solo un proceso puede ejecutar la recepción utilizando el concepto de exclusión mutua. Buzón mutex Se crea que es compartido por n procesos. El remitente no bloquea y envía el mensaje. El primer proceso que ejecute la recepción ingresará a la sección crítica y todos los demás procesos se bloquearán y esperarán.
Ahora, analicemos el problema Productor-Consumidor utilizando el concepto de paso de mensajes. El productor coloca artículos (dentro de los mensajes) en el buzón y el consumidor puede consumir un artículo cuando al menos hay un mensaje presente en el buzón. El código se proporciona a continuación:
Código de productor
C
void> Producer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Consumer, &m);> >item = produce();> >build_message(&m , item ) ;> >send(Consumer, &m);> >}> >}> |
>
>
Código del Consumidor
C
void> Consumer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Producer, &m);> >item = extracted_item();> >send(Producer, &m);> >consume_item(item);> >}> >}> |
>
>
Ejemplos de sistemas IPC
- Posix: utiliza el método de memoria compartida.
- Mach: utiliza el paso de mensajes
- Windows XP: utiliza la transmisión de mensajes mediante llamadas a procedimientos locales
Comunicación en Arquitectura cliente/servidor:
Hay varios mecanismos:
- Tubo
- Enchufe
- Llamadas a procedimientos remotos (RPC)
Los tres métodos anteriores se analizarán en artículos posteriores, ya que todos ellos son bastante conceptuales y merecen sus propios artículos separados.
Referencias:
- Conceptos de sistemas operativos de Galvin et al.
- Apuntes de conferencias/ppt de Ariel J. Frank, Universidad Bar-Ilan
La comunicación entre procesos (IPC) es el mecanismo a través del cual los procesos o subprocesos pueden comunicarse e intercambiar datos entre sí en una computadora o a través de una red. IPC es un aspecto importante de los sistemas operativos modernos, ya que permite que diferentes procesos trabajen juntos y compartan recursos, lo que conduce a una mayor eficiencia y flexibilidad.
Ventajas de la PCI:
- Permite que los procesos se comuniquen entre sí y compartan recursos, lo que lleva a una mayor eficiencia y flexibilidad.
- Facilita la coordinación entre múltiples procesos, lo que conduce a un mejor rendimiento general del sistema.
- Permite la creación de sistemas distribuidos que pueden abarcar múltiples computadoras o redes.
- Se puede utilizar para implementar varios protocolos de sincronización y comunicación, como semáforos, tuberías y sockets.
Desventajas de la PCI:
- Aumenta la complejidad del sistema, lo que dificulta su diseño, implementación y depuración.
- Puede introducir vulnerabilidades de seguridad, ya que los procesos pueden acceder o modificar datos pertenecientes a otros procesos.
- Requiere una gestión cuidadosa de los recursos del sistema, como la memoria y el tiempo de CPU, para garantizar que las operaciones de IPC no degraden el rendimiento general del sistema.
Puede provocar inconsistencias en los datos si varios procesos intentan acceder o modificar los mismos datos al mismo tiempo. - En general, las ventajas de IPC superan las desventajas, ya que es un mecanismo necesario para los sistemas operativos modernos y permite que los procesos trabajen juntos y compartan recursos de una manera flexible y eficiente. Sin embargo, se debe tener cuidado al diseñar e implementar sistemas IPC cuidadosamente, para evitar posibles vulnerabilidades de seguridad y problemas de rendimiento.
Más referencia:
http://nptel.ac.in/courses/106108101/pdf/Lecture_Notes/Mod%207_LN.pdf
https://www.youtube.com/watch?v=lcRqHwIn5Dk