BERT, un acrónimo para representaciones de codificadores bidireccionales de transformadores , se presenta como una fuente abierta marco de aprendizaje automático diseñado para el ámbito de procesamiento del lenguaje natural (PNL) . Este marco, que se originó en 2018, fue elaborado por investigadores de Google AI Language. El artículo tiene como objetivo explorar la arquitectura, funcionamiento y aplicaciones de BERT .
¿Qué es BERT?
BERT (representaciones de codificador bidireccional de transformadores) aprovecha una red neuronal basada en transformadores para comprender y generar un lenguaje similar al humano. BERT emplea una arquitectura de solo codificador. En el original Arquitectura del transformador , hay módulos codificadores y decodificadores. La decisión de utilizar una arquitectura de solo codificador en BERT sugiere un énfasis principal en comprender las secuencias de entrada en lugar de generar secuencias de salida.
Enfoque bidireccional de BERT
Los modelos de lenguaje tradicionales procesan el texto de forma secuencial, ya sea de izquierda a derecha o de derecha a izquierda. Este método limita la conciencia del modelo al contexto inmediato que precede a la palabra objetivo. BERT utiliza un enfoque bidireccional considerando el contexto izquierdo y derecho de las palabras de una oración; en lugar de analizar el texto secuencialmente, BERT analiza todas las palabras de una oración simultáneamente.
Ejemplo: La orilla está situada en la _______ del río.
En un modelo unidireccional, la comprensión del espacio en blanco dependería en gran medida de las palabras anteriores, y el modelo podría tener dificultades para discernir si banco se refiere a una institución financiera o a la orilla del río.
BERT, al ser bidireccional, considera simultáneamente tanto el contexto izquierdo (la orilla está situada en) como el derecho (del río), lo que permite una comprensión más matizada. Se comprende que la palabra que falta probablemente esté relacionada con la ubicación geográfica del banco, lo que demuestra la riqueza contextual que aporta el enfoque bidireccional.
Entrenamiento previo y ajuste
El modelo BERT pasa por un proceso de dos pasos:
- Capacitación previa sobre grandes cantidades de texto sin etiquetar para aprender incrustaciones contextuales.
- Ajuste de datos etiquetados para específicos PNL tareas.
Capacitación previa en big data
- BERT está previamente entrenado en una gran cantidad de datos de texto sin etiquetar. El modelo aprende incrustaciones contextuales, que son representaciones de palabras que tienen en cuenta el contexto que las rodea en una oración.
- BERT participa en varias tareas previas al entrenamiento sin supervisión. Por ejemplo, podría aprender a predecir las palabras que faltan en una oración (modelo de lenguaje enmascarado o tarea MLM), comprender la relación entre dos oraciones o predecir la siguiente oración de un par.
Ajuste fino de datos etiquetados
- Después de la fase previa a la capacitación, el modelo BERT, armado con sus incorporaciones contextuales, se ajusta para tareas específicas de procesamiento del lenguaje natural (PLN). Este paso adapta el modelo a aplicaciones más específicas adaptando su comprensión general del lenguaje a los matices de la tarea particular.
- BERT se ajusta utilizando datos etiquetados específicos para las tareas posteriores de interés. Estas tareas podrían incluir análisis de sentimientos, respuesta a preguntas, reconocimiento de entidad nombrada , o cualquier otra aplicación de PNL. Los parámetros del modelo se ajustan para optimizar su rendimiento según los requisitos particulares de la tarea en cuestión.
La arquitectura unificada de BERT le permite adaptarse a diversas tareas posteriores con modificaciones mínimas, lo que la convierte en una herramienta versátil y altamente efectiva en comprensión del lenguaje natural y procesamiento.
¿Cómo funciona BERT?
BERT está diseñado para generar un modelo de lenguaje, por lo que solo se utiliza el mecanismo codificador. La secuencia de tokens se envía al codificador Transformer. Estos tokens primero se integran en vectores y luego se procesan en la red neuronal. La salida es una secuencia de vectores, cada uno correspondiente a un token de entrada, que proporciona representaciones contextualizadas.
Al entrenar modelos de lenguaje, definir un objetivo de predicción es un desafío. Muchos modelos predicen la siguiente palabra en una secuencia, lo cual es un enfoque direccional y puede limitar el aprendizaje del contexto. BERT aborda este desafío con dos estrategias de formación innovadoras:
- Modelo de lenguaje enmascarado (MLM)
- Predicción de la siguiente oración (NSP)
1. Modelo de lenguaje enmascarado (MLM)
En el proceso de preentrenamiento de BERT, se enmascara una parte de las palabras en cada secuencia de entrada y el modelo se entrena para predecir los valores originales de estas palabras enmascaradas en función del contexto proporcionado por las palabras circundantes.
En lenguaje sencillo,
- Palabras de enmascaramiento: Antes de que BERT aprenda de las oraciones, oculta algunas palabras (alrededor del 15%) y las reemplaza con un símbolo especial, como [MASCARA].
- Adivinando palabras ocultas: El trabajo de BERT es descubrir cuáles son estas palabras ocultas observando las palabras que las rodean. Es como un juego de adivinanzas en el que faltan algunas palabras y BERT intenta completar los espacios en blanco.
- Cómo aprende BERT:
- BERT agrega una capa especial encima de su sistema de aprendizaje para hacer estas conjeturas. Luego comprueba qué tan cerca están sus conjeturas de las palabras ocultas reales.
- Lo hace convirtiendo sus conjeturas en probabilidades y diciendo: Creo que esta palabra es X y estoy muy seguro de ello.
- Atención especial a las palabras ocultas
- El objetivo principal de BERT durante la formación es corregir estas palabras ocultas. Le importa menos predecir las palabras que no están ocultas.
- Esto se debe a que el verdadero desafío es descubrir las partes que faltan, y esta estrategia ayuda a BERT a ser realmente bueno en la comprensión del significado y el contexto de las palabras.
En términos técnicos,
- BERT agrega una capa de clasificación encima de la salida del codificador. Esta capa es crucial para predecir las palabras enmascaradas.
- Los vectores de salida de la capa de clasificación se multiplican por la matriz de incrustación, transformándolos en la dimensión de vocabulario. Este paso ayuda a alinear las representaciones predichas con el espacio de vocabulario.
- La probabilidad de cada palabra del vocabulario se calcula utilizando la Función de activación SoftMax . Este paso genera una distribución de probabilidad sobre todo el vocabulario para cada posición enmascarada.
- La función de pérdida utilizada durante el entrenamiento considera únicamente la predicción de los valores enmascarados. El modelo es penalizado por la desviación entre sus predicciones y los valores reales de las palabras enmascaradas.
- El modelo converge más lentamente que los modelos direccionales. Esto se debe a que, durante el entrenamiento, BERT solo se preocupa por predecir los valores enmascarados, ignorando la predicción de las palabras no enmascaradas. La mayor conciencia del contexto lograda a través de esta estrategia compensa la convergencia más lenta.
2. Predicción de la siguiente oración (NSP)
BERT predice si la segunda oración está conectada con la primera. Esto se hace transformando la salida del token [CLS] en un vector con forma de 2 × 1 usando una capa de clasificación, y luego calculando la probabilidad de si la segunda oración sigue a la primera usando SoftMax.
- En el proceso de capacitación, BERT aprende a comprender la relación entre pares de oraciones, prediciendo si la segunda oración sigue a la primera en el documento original.
- El 50% de los pares de entrada tiene la segunda oración como oración posterior en el documento original, y el otro 50% tiene una oración elegida al azar.
- Ayudar al modelo a distinguir entre pares de oraciones conectadas y desconectadas. La entrada se procesa antes de ingresar al modelo:
- Se inserta un token [CLS] al comienzo de la primera oración y se agrega un token [SEP] al final de cada oración.
- A cada token se le agrega una oración incrustada que indica la oración A o la oración B.
- Una incrustación posicional indica la posición de cada token en la secuencia.
- BERT predice si la segunda oración está conectada con la primera. Esto se hace transformando la salida del token [CLS] en un vector con forma de 2 × 1 usando una capa de clasificación, y luego calculando la probabilidad de si la segunda oración sigue a la primera usando SoftMax.
Durante el entrenamiento del modelo BERT, el LM enmascarado y la predicción de la siguiente oración se entrenan juntos. El modelo tiene como objetivo minimizar la función de pérdida combinada de Masked LM y Next Sentence Prediction, lo que lleva a un modelo de lenguaje robusto con capacidades mejoradas para comprender el contexto dentro de las oraciones y las relaciones entre oraciones.
¿Por qué entrenar juntos LM enmascarado y Predicción de la siguiente oración?
Masked LM ayuda a BERT a comprender el contexto dentro de una oración y Predicción de la siguiente oración ayuda a BERT a comprender la conexión o relación entre pares de oraciones. Por lo tanto, entrenar ambas estrategias juntas garantiza que BERT aprenda una comprensión amplia e integral del lenguaje, capturando tanto los detalles dentro de las oraciones como el flujo entre oraciones.
Arquitecturas BERT
La arquitectura de BERT es un codificador de transformador bidireccional multicapa que es bastante similar al modelo de transformador. Una arquitectura de transformador es una red codificador-decodificador que utiliza autoatención en el lado del codificador y atención en el lado del decodificador.
- BERTBASEtiene 1 2 capas en la pila del codificador mientras BERTGRANDEtiene 24 capas en la pila del codificador . Estos son más que la arquitectura Transformer descrita en el artículo original ( 6 capas de codificador ).
- Las arquitecturas BERT (BASE y LARGE) también tienen redes feedforward más grandes (768 y 1024 unidades ocultas respectivamente), y más cabezas de atención (12 y 16 respectivamente) que la arquitectura Transformer sugerida en el artículo original. Contiene 512 unidades ocultas y 8 cabezales de atención .
- BERTBASEcontiene 110M de parámetros mientras que BERTGRANDETiene 340M de parámetros.

Arquitectura BERT BASE y BERT LARGE.
Este modelo toma el CLS token como entrada primero, luego le sigue una secuencia de palabras como entrada. Aquí CLS es un token de clasificación. Luego pasa la entrada a las capas anteriores. Cada capa se aplica autoatención y pasa el resultado a través de una red de avance, luego lo pasa al siguiente codificador. El modelo genera un vector de tamaño oculto ( 768 para la BASE BERT). Si queremos generar un clasificador de este modelo, podemos tomar la salida correspondiente al token CLS.
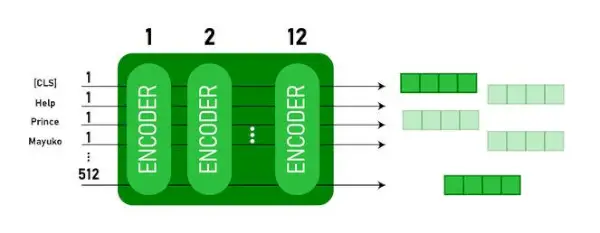
Salida BERT como incrustaciones
Ahora, este vector entrenado se puede utilizar para realizar una serie de tareas como clasificación, traducción, etc. Por ejemplo, el documento logra excelentes resultados con solo usar una sola capa. Red neuronal en el modelo BERT en la tarea de clasificación.
¿Cómo utilizar el modelo BERT en PNL?
BERT se puede utilizar para diversas tareas de procesamiento del lenguaje natural (NLP), como:
1. Tarea de clasificación
- BERT se puede utilizar para tareas de clasificación como análisis de los sentimientos , el objetivo es clasificar el texto en diferentes categorías (positivo/negativo/neutro), BERT se puede emplear agregando una capa de clasificación en la parte superior de la salida del Transformador para el token [CLS].
- El token [CLS] representa la información agregada de toda la secuencia de entrada. Esta representación agrupada se puede utilizar como entrada para una capa de clasificación para hacer predicciones para la tarea específica.
2. Respuesta a preguntas
- En tareas de respuesta a preguntas, donde se requiere que el modelo ubique y marque la respuesta dentro de una secuencia de texto determinada, se puede entrenar BERT para este propósito.
- BERT está capacitado para responder preguntas aprendiendo dos vectores adicionales que marcan el principio y el final de la respuesta. Durante el entrenamiento, el modelo recibe preguntas y pasajes correspondientes, y aprende a predecir las posiciones inicial y final de la respuesta dentro del pasaje.
3. Reconocimiento de entidad nombrada (NER)
- BERT se puede utilizar para NER, donde el objetivo es identificar y clasificar entidades (por ejemplo, persona, organización, fecha) en una secuencia de texto.
- Un modelo NER basado en BERT se entrena tomando el vector de salida de cada token del Transformador y alimentándolo en una capa de clasificación. La capa predice la etiqueta de entidad nombrada para cada token, indicando el tipo de entidad que representa.
¿Cómo tokenizar y codificar texto usando BERT?
Para tokenizar y codificar texto usando BERT, usaremos la biblioteca 'transformer' en Python.
Comando para instalar transformadores:
!pip install transformers>
- Cargaremos el tokenize BERT previamente entrenado con un vocabulario en mayúsculas usando BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.codificar(texto) tokeniza el texto de entrada y lo convierte en una secuencia de ID de token.
- imprimir (ID de token:, codificación) Imprime los ID de los tokens obtenidos después de la codificación.
- tokenizer.convert_ids_to_tokens(codificación) convierte los ID de los tokens nuevamente en sus tokens correspondientes.
- imprimir(Fichas:, fichas) imprime los tokens obtenidos después de convertir los ID de los tokens
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Producción:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> El tokenizador.codificar El método agrega el especial. [CLS] – clasificación y [SEP] – separador tokens al principio y al final de la secuencia codificada.
Aplicación de BERT
BERT se utiliza para:
- Representación de texto: BERT se utiliza para generar incrustaciones de palabras o representaciones de palabras en una oración.
- Reconocimiento de entidad nombrada (NER) : BERT se puede ajustar para tareas de reconocimiento de entidades con nombre, donde el objetivo es identificar entidades como nombres de personas, organizaciones, ubicaciones, etc., en un texto determinado.
- Clasificación de texto: BERT se utiliza ampliamente para tareas de clasificación de texto, incluido el análisis de opiniones, la detección de spam y la categorización de temas. Ha demostrado un excelente rendimiento en la comprensión y clasificación del contexto de datos textuales.
- Sistemas de respuesta a preguntas: BERT se ha aplicado a sistemas de respuesta a preguntas, donde el modelo está entrenado para comprender el contexto de una pregunta y proporcionar respuestas relevantes. Esto es particularmente útil para tareas como la comprensión lectora.
- Máquina traductora: Las incorporaciones contextuales de BERT se pueden aprovechar para mejorar los sistemas de traducción automática. El modelo captura los matices del lenguaje que son cruciales para una traducción precisa.
- Resumen de texto: BERT se puede utilizar para resúmenes de textos abstractos, donde el modelo genera resúmenes concisos y significativos de textos más largos al comprender el contexto y la semántica.
- IA conversacional: BERT se emplea en la construcción de sistemas de inteligencia artificial conversacionales, como chatbots, asistentes virtuales y sistemas de diálogo. Su capacidad para captar el contexto lo hace eficaz para comprender y generar respuestas en lenguaje natural.
- Similitud semántica: Las incorporaciones BERT se pueden utilizar para medir la similitud semántica entre oraciones o documentos. Esto es valioso en tareas como la detección de duplicados, la identificación de paráfrasis y la recuperación de información.
BERT frente a GPT
La diferencia entre BERT y GPT es la siguiente:
| BERT | GPT | |
|---|---|---|
| Arquitectura | BERT está diseñado para el aprendizaje de representación bidireccional. Utiliza un objetivo de modelo de lenguaje enmascarado, donde predice las palabras que faltan en una oración basándose tanto en el contexto izquierdo como en el derecho. | GPT, por otro lado, está diseñado para el modelado de lenguaje generativo. Predice la siguiente palabra de una oración dado el contexto anterior, utilizando un enfoque autorregresivo unidireccional. |
| Objetivos previos al entrenamiento | BERT está previamente entrenado utilizando un objetivo de modelo de lenguaje enmascarado y predicción de la siguiente oración. Se centra en capturar el contexto bidireccional y comprender las relaciones entre las palabras de una oración. | GPT está previamente entrenado para predecir la siguiente palabra en una oración, lo que anima al modelo a aprender una representación coherente del lenguaje y generar secuencias contextualmente relevantes. |
| Comprensión del contexto | BERT es eficaz para tareas que requieren una comprensión profunda del contexto y las relaciones dentro de una oración, como la clasificación de texto, el reconocimiento de entidades nombradas y la respuesta a preguntas. | GPT es fuerte en generar texto coherente y contextualmente relevante. A menudo se utiliza en tareas creativas, sistemas de diálogo y tareas que requieren la generación de secuencias de lenguaje natural. |
| Tipos de tareas y casos de uso
| Se utiliza comúnmente en tareas como clasificación de texto, reconocimiento de entidades con nombre, análisis de sentimientos y respuesta a preguntas. | Aplicado a tareas como generación de textos, sistemas de diálogo, resúmenes y escritura creativa. |
| Ajuste fino versus aprendizaje con pocas posibilidades | BERT a menudo se ajusta en tareas posteriores específicas con datos etiquetados para adaptar sus representaciones previamente entrenadas a la tarea en cuestión. | GPT está diseñado para realizar un aprendizaje en pocas etapas, donde puede generalizarse a nuevas tareas con datos de entrenamiento mínimos específicos de la tarea. |
Verifique también:
- Clasificación de sentimientos utilizando BERT
- ¿Cómo generar incrustaciones de Word usando BERT?
- Modelo BART para autocompletar texto en PNL
- Clasificación de comentarios tóxicos utilizando BERT
- Predicción de la siguiente oración usando BERT
Preguntas frecuentes (FAQ)
P. ¿Para qué se utiliza BERT?
BERT se utiliza para realizar tareas de PNL como representación de texto, reconocimiento de entidades con nombre, clasificación de texto, sistemas de preguntas y respuestas, traducción automática, resumen de texto y más.
P. ¿Cuáles son las ventajas del modelo BERT?
El modelo de lenguaje BERT destaca por su amplia formación previa en múltiples idiomas, ofreciendo una amplia cobertura lingüística respecto a otros modelos. Esto hace que BERT sea particularmente ventajoso para proyectos que no están basados en inglés, ya que proporciona representaciones contextuales sólidas y comprensión semántica en una amplia gama de idiomas, lo que mejora su versatilidad en aplicaciones multilingües.
P. ¿Cómo funciona BERT para el análisis de sentimientos?
BERT sobresale en el análisis de sentimientos al aprovechar su aprendizaje de representación bidireccional para capturar matices contextuales, significados semánticos y estructuras sintácticas dentro de un texto determinado. Esto permite a BERT comprender el sentimiento expresado en una oración al considerar las relaciones entre las palabras, lo que genera resultados de análisis de sentimiento altamente efectivos.
inicialización de la lista de Python
P. ¿Google se basa en BERT?
BERT y rangocerebro son componentes del algoritmo de búsqueda de Google para procesar consultas y contenido de páginas web para obtener una mejor comprensión y mejorar los resultados de búsqueda.