- El algoritmo del vector de distancia es un algoritmo dinámico.
- Se utiliza principalmente en ARPANET y RIP.
- Cada enrutador mantiene una tabla de distancias conocida como Vector .
Tres claves para comprender el funcionamiento del algoritmo de enrutamiento por vector de distancia:
Algoritmo de enrutamiento por vector de distancia
sea dX(y) sea el costo de la ruta de menor costo desde el nodo x al nodo y. Los menores costos están relacionados por la ecuación de Bellman-Ford,
d<sub>x</sub>(y) = min<sub>v</sub>{c(x,v) + d<sub>v</sub>(y)} Dónde el minv es la ecuación tomada para todos los x vecinos. Después de viajar de x a v, si consideramos el camino de menor costo de v a y, el costo del camino será c(x,v)+den(y). El menor costo de xay es el mínimo de c(x,v)+den(y) se hizo cargo de todos los vecinos.
Con el algoritmo de enrutamiento por vector de distancia, el nodo x contiene la siguiente información de enrutamiento:
- Para cada vecino v, el costo c(x,v) es el costo del camino desde x hasta el vecino directamente adjunto, v.
- El vector distancia x, es decir, DX= [DX(y) : y en N ], que contiene su costo para todos los destinos, y, en N.
- El vector distancia de cada uno de sus vecinos, es decir, Den= [Den(y) : y en N ] para cada vecino v de x.
El enrutamiento por vector de distancia es un algoritmo asincrónico en el que el nodo x envía la copia de su vector de distancia a todos sus vecinos. Cuando el nodo x recibe el nuevo vector de distancia de uno de sus vectores vecinos, v, guarda el vector de distancia de v y usa la ecuación de Bellman-Ford para actualizar su propio vector de distancia. La ecuación se da a continuación:
cadena a carácter
d<sub>x</sub>(y) = min<sub>v</sub>{ c(x,v) + d<sub>v</sub>(y)} for each node y in N El nodo x ha actualizado su propia tabla de vectores de distancia utilizando la ecuación anterior y envía su tabla actualizada a todos sus vecinos para que puedan actualizar sus propios vectores de distancia.
Algoritmo
At each node x, <p> <strong>Initialization</strong> </p> for all destinations y in N: D<sub>x</sub>(y) = c(x,y) // If y is not a neighbor then c(x,y) = ∞ for each neighbor w D<sub>w</sub>(y) = ? for all destination y in N. for each neighbor w send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to w <strong>loop</strong> <strong>wait</strong> (until I receive any distance vector from some neighbor w) for each y in N: D<sub>x</sub>(y) = minv{c(x,v)+D<sub>v</sub>(y)} If D<sub>x</sub>(y) is changed for any destination y Send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to all neighbors <strong>forever</strong> Nota: En el algoritmo de vector de distancia, el nodo x actualiza su tabla cuando ve algún cambio de costo en uno de los nodos directamente vinculados o recibe cualquier actualización de vector de algún vecino.
Entendamos a través de un ejemplo:
Compartiendo información
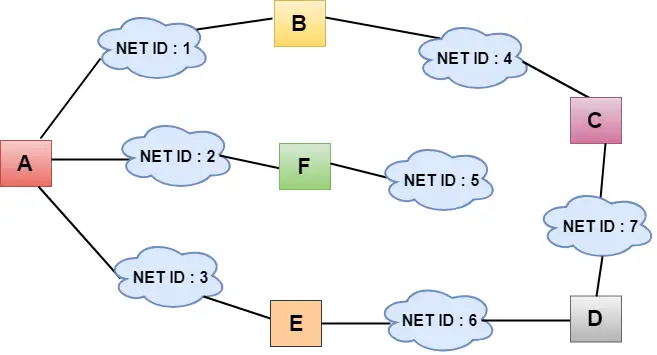
- En la figura anterior, cada nube representa la red y el número dentro de la nube representa la ID de la red.
- Todas las LAN están conectadas mediante enrutadores y están representadas en cuadros etiquetados como A, B, C, D, E, F.
- El algoritmo de enrutamiento por vector de distancia simplifica el proceso de enrutamiento al asumir que el costo de cada enlace es una unidad. Por tanto, la eficiencia de la transmisión se puede medir por el número de enlaces para llegar al destino.
- En el enrutamiento por vector de distancia, el costo se basa en el recuento de saltos.

En la figura anterior, observamos que el enrutador envía el conocimiento a los vecinos inmediatos. Los vecinos añaden este conocimiento a su propio conocimiento y envían la tabla actualizada a sus propios vecinos. De esta forma, los enrutadores obtienen su propia información más la nueva información sobre los vecinos.
Tabla de ruteo
Se producen dos procesos:
- Creando la tabla
- Actualizando la tabla
Creando la tabla
Inicialmente, se crea la tabla de enrutamiento para cada enrutador que contiene al menos tres tipos de información, como ID de red, costo y siguiente salto.


- En la figura anterior, se muestran las tablas de enrutamiento originales de todos los enrutadores. En una tabla de enrutamiento, la primera columna representa el ID de la red, la segunda columna representa el costo del enlace y la tercera columna está vacía.
- Estas tablas de enrutamiento se envían a todos los vecinos.
Por ejemplo:
A sends its routing table to B, F & E. B sends its routing table to A & C. C sends its routing table to B & D. D sends its routing table to E & C. E sends its routing table to A & D. F sends its routing table to A.
Actualizando la tabla
- Cuando A recibe una tabla de enrutamiento de B, utiliza su información para actualizar la tabla.
- La tabla de enrutamiento de B muestra cómo los paquetes pueden moverse a las redes 1 y 4.
- El B es vecino del enrutador A, los paquetes de A a B pueden llegar en un solo salto. Entonces, se suma 1 a todos los costos indicados en la tabla de B y la suma será el costo para llegar a una red en particular.

- Después del ajuste, A combina esta tabla con su propia tabla para crear una tabla combinada.

- La tabla combinada puede contener algunos datos duplicados. En la figura anterior, la tabla combinada del enrutador A contiene los datos duplicados, por lo que conserva solo aquellos datos que tienen el costo más bajo. Por ejemplo, A puede enviar los datos a la red 1 de dos formas. El primero, que no utiliza ningún enrutador siguiente, por lo que cuesta un salto. El segundo requiere dos saltos (A a B, luego B a la Red 1). La primera opción tiene el coste más bajo, por lo que se mantiene y se descarta la segunda.

- El proceso de creación de la tabla de enrutamiento continúa para todos los enrutadores. Cada enrutador recibe la información de los vecinos y actualiza la tabla de enrutamiento.
Las tablas de enrutamiento finales de todos los enrutadores se proporcionan a continuación:
