Un cursor en SQL Server es una d Objeto de base de datos que nos permite recuperar cada fila a la vez y manipular sus datos. . Un cursor no es más que un puntero a una fila. Siempre se usa junto con una declaración SELECT. Suele ser una colección de SQL lógica que recorre un número predeterminado de filas una por una. Una ilustración simple del cursor es cuando tenemos una base de datos extensa de registros de trabajadores y queremos calcular el salario de cada trabajador después de deducir impuestos y licencias.
El servidor SQL El propósito del cursor es actualizar los datos fila por fila, cambiarlos o realizar cálculos que no son posibles cuando recuperamos todos los registros a la vez. . También es útil para realizar tareas administrativas como copias de seguridad de bases de datos de SQL Server en orden secuencial. Los cursores se utilizan principalmente en los procesos de desarrollo, DBA y ETL.
Este artículo explica todo sobre el cursor de SQL Server, como el ciclo de vida del cursor, por qué y cuándo se usa el cursor, cómo implementar cursores, sus limitaciones y cómo podemos reemplazar un cursor.
Ciclo de vida del cursor
Podemos describir el ciclo de vida de un cursor en el cinco secciones diferentes como sigue:
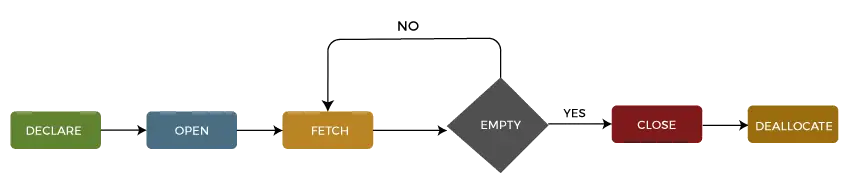
1: declarar cursor
El primer paso es declarar el cursor utilizando la siguiente declaración SQL:
java leer archivo csv
DECLARE cursor_name CURSOR FOR select_statement;
Podemos declarar un cursor especificando su nombre con el tipo de datos CURSOR después de la palabra clave DECLARE. Luego, escribiremos la instrucción SELECT que define la salida del cursor.
2: abrir cursor
Es un segundo paso en el que abrimos el cursor para almacenar los datos recuperados del conjunto de resultados. Podemos hacer esto usando la siguiente declaración SQL:
OPEN cursor_name;
3: recuperar el cursor
Es un tercer paso en el que las filas se pueden recuperar una por una o en un bloque para realizar manipulación de datos como operaciones de inserción, actualización y eliminación en la fila actualmente activa en el cursor. Podemos hacer esto usando la siguiente declaración SQL:
FETCH NEXT FROM cursor INTO variable_list;
También podemos utilizar el Función @@FETCHSTATUS en SQL Server para obtener el estado del cursor de instrucción FETCH más reciente que se ejecutó contra el cursor. El BUSCAR La declaración fue exitosa cuando @@FETCHSTATUS da cero resultados. El MIENTRAS La declaración se puede utilizar para recuperar todos los registros del cursor. El siguiente código lo explica más claramente:
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4: Cerrar cursor
Es un cuarto paso en el que el cursor debe cerrarse después de que terminemos de trabajar con el cursor. Podemos hacer esto usando la siguiente declaración SQL:
CLOSE cursor_name;
5: desasignar cursor
Es el quinto y último paso en el que borraremos la definición del cursor y liberaremos todos los recursos del sistema asociados con el cursor. Podemos hacer esto usando la siguiente declaración SQL:
DEALLOCATE cursor_name;
Usos del cursor de SQL Server
Sabemos que los sistemas de administración de bases de datos relacionales, incluido SQL Server, son excelentes para manejar datos en un conjunto de filas llamado conjuntos de resultados. Por ejemplo , tenemos una mesa tabla_producto que contiene las descripciones de los productos. Si queremos actualizar el precio del producto, luego lo siguiente ' ACTUALIZAR' La consulta actualizará todos los registros que coincidan con la condición en el ' DÓNDE' cláusula:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
A veces, la aplicación necesita procesar las filas de forma única, es decir, fila por fila en lugar de todo el conjunto de resultados a la vez. Podemos realizar este proceso utilizando cursores en SQL Server. Antes de usar el cursor, debemos saber que los cursores tienen muy mal rendimiento, por lo que siempre se deben usar solo cuando no haya otra opción que no sea el cursor.
El cursor usa la misma técnica que usamos bucles como FOREACH, FOR, WHILE, DO WHILE para iterar un objeto a la vez en todos los lenguajes de programación. Por lo tanto, podría elegirse porque aplica la misma lógica que el proceso de bucle del lenguaje de programación.
Linux que
Tipos de cursores en SQL Server
Los siguientes son los diferentes tipos de cursores en SQL Server que se enumeran a continuación:
- Cursores estáticos
- Cursores dinámicos
- Cursores solo hacia adelante
- Cursores de conjunto de teclas

Cursores estáticos
El conjunto de resultados mostrado por el cursor estático es siempre el mismo que cuando se abrió el cursor por primera vez. Dado que el cursor estático almacenará el resultado en tempdb , ellos estan siempre solo lectura . Podemos utilizar el cursor estático para movernos tanto hacia adelante como hacia atrás. A diferencia de otros cursores, es más lento y consume más memoria. Como resultado, podemos usarlo sólo cuando es necesario desplazarnos y otros cursores no son adecuados.
Este cursor muestra filas que se eliminaron de la base de datos después de abrirla. Un cursor estático no representa ninguna operación INSERTAR, ACTUALIZAR o ELIMINAR (a menos que el cursor se cierre y se vuelva a abrir).
Cursores dinámicos
Los cursores dinámicos son opuestos a los cursores estáticos que nos permiten realizar las operaciones de actualización, eliminación e inserción de datos mientras el cursor está abierto. Es desplazable por defecto . Puede detectar todos los cambios realizados en las filas, el orden y los valores del conjunto de resultados, ya sea que los cambios se produzcan dentro o fuera del cursor. Fuera del cursor, no podemos ver las actualizaciones hasta que se confirmen.
Cursores solo hacia adelante
Es el tipo de cursor predeterminado y más rápido entre todos los cursores. Se llama cursor de sólo avance porque avanza sólo a través del conjunto de resultados . Este cursor no admite el desplazamiento. Sólo puede recuperar filas desde el principio hasta el final del conjunto de resultados. Nos permite realizar operaciones de inserción, actualización y eliminación. Aquí, el efecto de las operaciones de inserción, actualización y eliminación realizadas por el usuario que afectan las filas en el conjunto de resultados es visible a medida que las filas se recuperan del cursor. Cuando se obtuvo la fila, no podemos ver los cambios realizados en las filas a través del cursor.
Los cursores de solo avance se clasifican en tres tipos:
- Conjunto de teclas Forward_Only
- Forward_Only estático
- Avance rápido

Cursores controlados por conjuntos de teclas
Esta funcionalidad del cursor se encuentra entre un cursor estático y uno dinámico en cuanto a su capacidad para detectar cambios. No siempre puede detectar cambios en la pertenencia y el orden del conjunto de resultados como un cursor estático. Puede detectar cambios en los valores de las filas del conjunto de resultados como si fuera un cursor dinámico. Sólo puede pasar del primero al último y del último a la primera fila . El orden y la membresía se fijan cada vez que se abre este cursor.
Es operado por un conjunto de identificadores únicos iguales a las claves del conjunto de claves. El conjunto de claves está determinado por todas las filas que calificaron la instrucción SELECT cuando se abrió el cursor por primera vez. También puede detectar cualquier cambio en la fuente de datos, que admite operaciones de actualización y eliminación. Es desplazable de forma predeterminada.
Implementación del ejemplo
Implementemos el ejemplo del cursor en el servidor SQL. Podemos hacer esto creando primero una tabla llamada ' cliente ' usando la siguiente declaración:
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
A continuación, insertaremos valores en la tabla. Podemos ejecutar la siguiente declaración para agregar datos a una tabla:
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
Podemos verificar los datos ejecutando el SELECCIONAR declaración:
SELECT * FROM customer;
Después de ejecutar la consulta, podemos ver el siguiente resultado donde tenemos ocho filas en la mesa:

Ahora crearemos un cursor para mostrar los registros de clientes. Los siguientes fragmentos de código explican todos los pasos de la declaración o creación del cursor reuniendo todo:
vba
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Después de ejecutar un cursor, obtendremos el siguiente resultado:

Limitaciones del cursor de SQL Server
Un cursor tiene algunas limitaciones por lo que siempre debe usarse solo cuando no hay otra opción que el cursor. Estas limitaciones son:
- El cursor consume recursos de la red al requerir un viaje de ida y vuelta a la red cada vez que recupera un registro.
- Un cursor es un conjunto de punteros residentes en la memoria, lo que significa que ocupa algo de memoria que otros procesos podrían usar en nuestra máquina.
- Impone bloqueos en una parte de la tabla o en toda la tabla al procesar datos.
- El rendimiento y la velocidad del cursor son más lentos porque actualizan los registros de la tabla una fila a la vez.
- Los cursores son más rápidos que los bucles while, pero tienen más sobrecarga.
- El número de filas y columnas que se introducen en el cursor es otro aspecto que afecta la velocidad del cursor. Se refiere a cuánto tiempo lleva abrir el cursor y ejecutar una declaración de recuperación.
¿Cómo podemos evitar los cursores?
El trabajo principal de los cursores es recorrer la tabla fila por fila. La forma más sencilla de evitar los cursores se detalla a continuación:
Usando el bucle while de SQL
La forma más sencilla de evitar el uso de un cursor es mediante el uso de un bucle while que permita insertar un conjunto de resultados en la tabla temporal.
Funciones definidas por el usuario
A veces se utilizan cursores para calcular el conjunto de filas resultante. Podemos lograr esto utilizando una función definida por el usuario que cumpla con los requisitos.
Usando uniones
Join procesa solo aquellas columnas que cumplen con la condición especificada y, por lo tanto, reduce las líneas de código que brindan un rendimiento más rápido que los cursores en caso de que sea necesario procesar registros grandes.