En el mundo real, no todos los datos con los que trabajamos tienen una variable objetivo. Este tipo de datos no se pueden analizar mediante algoritmos de aprendizaje supervisado. Necesitamos la ayuda de algoritmos no supervisados. Uno de los tipos de análisis más populares en el aprendizaje no supervisado es segmentación de clientes para anuncios dirigidos o en imágenes médicas para encontrar áreas infectadas nuevas o desconocidas y muchos más casos de uso que analizaremos más adelante en este artículo.
Tabla de contenidos
- ¿Qué es la agrupación?
- Tipos de agrupación
- Usos de la agrupación
- Tipos de algoritmos de agrupación
- Aplicaciones del Clustering en diferentes campos:
- Preguntas frecuentes (FAQ) sobre la agrupación en clústeres
¿Qué es la agrupación?
La tarea de agrupar puntos de datos en función de su similitud entre sí se llama agrupación o análisis de conglomerados. Este método se define en la rama de Aprendizaje sin supervisión , que tiene como objetivo obtener información a partir de puntos de datos no etiquetados, es decir, a diferencia de aprendizaje supervisado No tenemos una variable objetivo.
La agrupación tiene como objetivo formar grupos de puntos de datos homogéneos a partir de un conjunto de datos heterogéneo. Evalúa la similitud en función de una métrica como la distancia euclidiana, la similitud del coseno, la distancia de Manhattan, etc. y luego agrupa los puntos con la puntuación de similitud más alta.
Por ejemplo, en el gráfico que se muestra a continuación, podemos ver claramente que se forman 3 grupos circulares en función de la distancia.
burlarse cuando sea
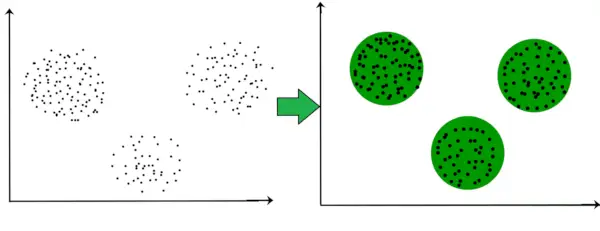
Ahora no es necesario que los racimos formados tengan forma circular. La forma de los grupos puede ser arbitraria. Hay muchos algoritmos que funcionan bien para detectar grupos de formas arbitrarias.
Por ejemplo, en el siguiente gráfico podemos ver que los grupos formados no tienen forma circular.
¿Cómo actualizo Java?

Tipos de agrupación
En términos generales, existen 2 tipos de agrupación que se pueden realizar para agrupar puntos de datos similares:
- Agrupación difícil: En este tipo de agrupación, cada punto de datos pertenece completamente o no a un grupo. Por ejemplo, digamos que hay 4 puntos de datos y tenemos que agruparlos en 2 grupos. Entonces, cada punto de datos pertenecerá al grupo 1 o al grupo 2.
| Puntos de datos | Clústeres |
|---|---|
| A | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Agrupación suave: En este tipo de agrupación, en lugar de asignar cada punto de datos a un grupo separado, se evalúa la probabilidad de que ese punto sea ese grupo. Por ejemplo, digamos que hay 4 puntos de datos y tenemos que agruparlos en 2 grupos. Por lo tanto, evaluaremos la probabilidad de que un punto de datos pertenezca a ambos grupos. Esta probabilidad se calcula para todos los puntos de datos.
| Puntos de datos | Probabilidad de C1 | Probabilidad de C2 |
| A | 0.91 | 0.09 |
| B | 0.3 | 0.7 |
| C | 0.17 | 0.83 |
| D | 1 | 0 |
Usos de la agrupación
Ahora, antes de comenzar con los tipos de algoritmos de agrupación, analizaremos los casos de uso de los algoritmos de agrupación. Los algoritmos de agrupamiento se utilizan principalmente para:
- Segmentación de mercado – Las empresas utilizan la agrupación para agrupar a sus clientes y utilizan anuncios dirigidos para atraer más audiencia.
- Análisis de redes sociales – Los sitios de redes sociales utilizan sus datos para comprender su comportamiento de navegación y brindarle recomendaciones de amigos específicas o recomendaciones de contenido.
- Imágenes médicas: los médicos utilizan la agrupación para descubrir áreas enfermas en imágenes de diagnóstico, como radiografías.
- Detección de anomalías – Para encontrar valores atípicos en un flujo de conjuntos de datos en tiempo real o pronosticar transacciones fraudulentas, podemos utilizar la agrupación para identificarlos.
- Simplifique el trabajo con conjuntos de datos grandes: a cada clúster se le asigna un ID de clúster una vez que se completa la agrupación. Ahora, puede reducir todo el conjunto de funciones de un conjunto de funciones a su ID de clúster. La agrupación en clústeres es eficaz cuando puede representar un caso complicado con una ID de clúster sencilla. Utilizando el mismo principio, agrupar datos puede simplificar conjuntos de datos complejos.
Hay muchos más casos de uso para la agrupación en clústeres, pero existen algunos de los casos de uso más importantes y comunes de la agrupación en clústeres. En el futuro, analizaremos los algoritmos de agrupación en clústeres que le ayudarán a realizar las tareas anteriores.
Tipos de algoritmos de agrupación
A nivel superficial, la agrupación ayuda en el análisis de datos no estructurados. Los gráficos, la distancia más corta y la densidad de los puntos de datos son algunos de los elementos que influyen en la formación de grupos. La agrupación es el proceso de determinar qué tan relacionados están los objetos en función de una métrica llamada medida de similitud. Las métricas de similitud son más fáciles de localizar en conjuntos más pequeños de características. Se vuelve más difícil crear medidas de similitud a medida que aumenta el número de características. Dependiendo del tipo de algoritmo de agrupamiento que se utilice en la minería de datos, se emplean varias técnicas para agrupar los datos de los conjuntos de datos. En esta parte, se describen las técnicas de agrupamiento. Varios tipos de algoritmos de agrupamiento son:
- Agrupación basada en centroides (métodos de partición)
- Agrupación basada en densidad (métodos basados en modelos)
- Agrupación basada en conectividad (agrupación jerárquica)
- Agrupación basada en distribución
Analizaremos cada uno de estos tipos brevemente.
1. Los métodos de partición son los algoritmos de agrupación en clústeres más sencillos. Agrupan puntos de datos en función de su cercanía. Generalmente, las medidas de similitud elegidas para estos algoritmos son la distancia euclidiana, la distancia de Manhattan o la distancia de Minkowski. Los conjuntos de datos se separan en un número predeterminado de grupos y cada grupo está referenciado por un vector de valores. Cuando se compara con el valor del vector, la variable de datos de entrada no muestra diferencias y se une al grupo.
El principal inconveniente de estos algoritmos es el requisito de que establezcamos el número de grupos, k, ya sea intuitiva o científicamente (utilizando el método Elbow) antes de que cualquier sistema de aprendizaje automático de agrupamiento comience a asignar los puntos de datos. A pesar de esto, sigue siendo el tipo de agrupación más popular. K-medias y K-medoides La agrupación en clústeres son algunos ejemplos de este tipo de agrupación.
lista enlazada y lista de matrices
2. Agrupación basada en densidad (métodos basados en modelos)
La agrupación basada en densidad, un método basado en modelos, encuentra grupos según la densidad de los puntos de datos. A diferencia de la agrupación basada en centroides, que requiere que el número de grupos esté predefinido y es sensible a la inicialización, la agrupación basada en densidad determina la cantidad de grupos automáticamente y es menos susceptible a las posiciones iniciales. Son excelentes para manejar grupos de diferentes tamaños y formas, lo que los hace ideales para conjuntos de datos con grupos superpuestos o de forma irregular. Estos métodos gestionan regiones de datos densas y escasas centrándose en la densidad local y pueden distinguir grupos con una variedad de morfologías.
Por el contrario, la agrupación basada en centroides, como k-medias, tiene problemas para encontrar grupos de formas arbitrarias. Debido a su número preestablecido de requisitos de clúster y su extrema sensibilidad al posicionamiento inicial de los centroides, los resultados pueden variar. Además, la tendencia de los enfoques basados en centroides a producir grupos esféricos o convexos restringe su capacidad para manejar grupos complicados o de forma irregular. En conclusión, la agrupación basada en densidad supera los inconvenientes de las técnicas basadas en centroides al elegir de forma autónoma los tamaños de los grupos, ser resistente a la inicialización y capturar con éxito grupos de diversos tamaños y formas. El algoritmo de agrupamiento basado en densidad más popular es DBSCAN .
3. Agrupación basada en conectividad (agrupación jerárquica)
Un método para ensamblar puntos de datos relacionados en grupos jerárquicos se denomina agrupamiento jerárquico. Inicialmente, cada punto de datos se tiene en cuenta como un grupo separado, que posteriormente se combina con los grupos que son más similares para formar un grupo grande que contiene todos los puntos de datos.
Piensa en cómo puedes organizar una colección de elementos en función de su similitud. Cada objeto comienza como su propio grupo en la base del árbol cuando se utiliza el agrupamiento jerárquico, lo que crea un dendrograma, una estructura similar a un árbol. Los pares de grupos más cercanos se combinan luego en grupos más grandes después de que el algoritmo examina qué tan similares son los objetos entre sí. Cuando cada objeto está en un grupo en la parte superior del árbol, el proceso de fusión ha finalizado. Explorar varios niveles de granularidad es una de las cosas divertidas de la agrupación jerárquica. Para obtener un número determinado de grupos, puede seleccionar cortar el dendograma a una altura determinada. Cuanto más similares sean dos objetos dentro de un grupo, más cercanos estarán. Es comparable a clasificar elementos según sus árboles genealógicos, donde los parientes más cercanos están agrupados y las ramas más anchas significan conexiones más generales. Hay 2 enfoques para la agrupación jerárquica:
- Agrupación divisiva : Sigue un enfoque de arriba hacia abajo, aquí consideramos que todos los puntos de datos forman parte de un gran grupo y luego este grupo se divide en grupos más pequeños.
- Agrupación aglomerativa : Sigue un enfoque ascendente, aquí consideramos que todos los puntos de datos son parte de grupos individuales y luego estos grupos se agrupan para formar un grupo grande con todos los puntos de datos.
4. Agrupación basada en la distribución
Al utilizar la agrupación basada en distribución, los puntos de datos se generan y organizan de acuerdo con su propensión a caer en la misma distribución de probabilidad (como gaussiana, binomial u otra) dentro de los datos. Los elementos de datos se agrupan mediante una distribución basada en probabilidad que se basa en distribuciones estadísticas. Se incluyen objetos de datos que tienen una mayor probabilidad de estar en el clúster. Es menos probable que un punto de datos se incluya en un grupo cuanto más lejos esté del punto central del grupo, que existe en cada grupo.
Un inconveniente notable de los enfoques basados en densidad y límites es la necesidad de especificar los grupos a priori para algunos algoritmos, y principalmente la definición de la forma del grupo para la mayor parte de los algoritmos. Debe haber al menos un ajuste o hiperparámetro seleccionado y, aunque hacerlo debería ser sencillo, hacerlo mal podría tener repercusiones imprevistas. La agrupación basada en distribución tiene una clara ventaja sobre los enfoques de agrupación basados en proximidad y centroides en términos de flexibilidad, precisión y estructura de agrupación. La cuestión clave es que, para evitar sobreajuste , muchos métodos de agrupación solo funcionan con datos simulados o fabricados, o cuando la mayor parte de los puntos de datos ciertamente pertenecen a una distribución preestablecida. El algoritmo de agrupamiento basado en distribución más popular es Modelo de mezcla gaussiana .
Aplicaciones del Clustering en diferentes campos:
- Marketing: Se puede utilizar para caracterizar y descubrir segmentos de clientes con fines de marketing.
- Biología: Puede utilizarse para clasificar entre diferentes especies de plantas y animales.
- Bibliotecas: Se utiliza para agrupar diferentes libros según temas e información.
- Seguro: Se utiliza para reconocer a los clientes, sus políticas e identificar los fraudes.
- Planificación de la ciudad: Se utiliza para agrupar casas y estudiar sus valores en función de su ubicación geográfica y otros factores presentes.
- Estudios de terremotos: Conociendo las zonas afectadas por el terremoto podemos determinar las zonas peligrosas.
- Procesamiento de imágenes : La agrupación en clústeres se puede utilizar para agrupar imágenes similares, clasificar imágenes según el contenido e identificar patrones en los datos de la imagen.
- Genética: La agrupación se utiliza para agrupar genes que tienen patrones de expresión similares e identificar redes de genes que trabajan juntos en procesos biológicos.
- Finanzas: La agrupación se utiliza para identificar segmentos de mercado en función del comportamiento del cliente, identificar patrones en los datos del mercado de valores y analizar el riesgo en las carteras de inversión.
- Servicio al Cliente: La agrupación se utiliza para agrupar las consultas y quejas de los clientes en categorías, identificar problemas comunes y desarrollar soluciones específicas.
- Fabricación : La agrupación se utiliza para agrupar productos similares, optimizar los procesos de producción e identificar defectos en los procesos de fabricación.
- Diagnostico medico: La agrupación se utiliza para agrupar pacientes con síntomas o enfermedades similares, lo que ayuda a realizar diagnósticos precisos e identificar tratamientos eficaces.
- Detección de fraude: La agrupación se utiliza para identificar patrones sospechosos o anomalías en transacciones financieras, lo que puede ayudar a detectar fraudes u otros delitos financieros.
- Análisis de tráfico: La agrupación se utiliza para agrupar patrones similares de datos de tráfico, como horas pico, rutas y velocidades, lo que puede ayudar a mejorar la planificación y la infraestructura del transporte.
- Análisis de redes sociales: La agrupación se utiliza para identificar comunidades o grupos dentro de las redes sociales, lo que puede ayudar a comprender el comportamiento, la influencia y las tendencias sociales.
- La seguridad cibernética: La agrupación en clústeres se utiliza para agrupar patrones similares de tráfico de red o comportamiento del sistema, lo que puede ayudar a detectar y prevenir ciberataques.
- Análisis climático: La agrupación se utiliza para agrupar patrones similares de datos climáticos, como temperatura, precipitación y viento, que pueden ayudar a comprender el cambio climático y su impacto en el medio ambiente.
- Análisis deportivo: La agrupación se utiliza para agrupar patrones similares de datos de rendimiento de jugadores o equipos, lo que puede ayudar a analizar las fortalezas y debilidades del jugador o equipo y a tomar decisiones estratégicas.
- Análisis del crimen: La agrupación se utiliza para agrupar patrones similares de datos sobre delitos, como ubicación, hora y tipo, lo que puede ayudar a identificar puntos críticos de delitos, predecir tendencias delictivas futuras y mejorar las estrategias de prevención del delito.
Conclusión
En este artículo analizamos la agrupación en clústeres, sus tipos y sus aplicaciones en el mundo real. Hay mucho más que cubrir en el aprendizaje no supervisado y el análisis de conglomerados es sólo el primer paso. Este artículo puede ayudarlo a comenzar con los algoritmos de agrupación en clústeres y ayudarlo a obtener un nuevo proyecto que pueda agregar a su cartera.
Preguntas frecuentes (FAQ) sobre la agrupación en clústeres
P. ¿Cuál es el mejor método de agrupación?
Los 10 principales algoritmos de agrupación son:
jdbc
- K-significa agrupación
- Agrupación jerárquica
- DBSCAN (agrupación espacial de aplicaciones con ruido basada en densidad)
- Modelos de mezcla gaussiana (GMM)
- Agrupación aglomerativa
- Agrupación espectral
- Agrupación de cambios medios
- Propagación por afinidad
- ÓPTICA (Ordenación de puntos para identificar la estructura de agrupación)
- Birch (reducción iterativa equilibrada y agrupación mediante jerarquías)
P. ¿Cuál es la diferencia entre agrupación y clasificación?
La principal diferencia entre agrupación y clasificación es que la clasificación es un algoritmo de aprendizaje supervisado y la agrupación es un algoritmo de aprendizaje no supervisado. Es decir, aplicamos la agrupación a aquellos conjuntos de datos que no tienen una variable objetivo.
P. ¿Cuáles son las ventajas del análisis de agrupamiento?
Los datos se pueden organizar en grupos significativos utilizando la sólida herramienta analítica del análisis de conglomerados. Puede utilizarlo para identificar segmentos, encontrar patrones ocultos y mejorar decisiones.
P. ¿Cuál es el método de agrupación en clústeres más rápido?
La agrupación de K-medias a menudo se considera el método de agrupación más rápido debido a su simplicidad y eficiencia computacional. Asigna iterativamente puntos de datos al centroide del grupo más cercano, lo que lo hace adecuado para conjuntos de datos grandes con baja dimensionalidad y un número moderado de grupos.
P. ¿Cuáles son las limitaciones de la agrupación?
Las limitaciones de la agrupación incluyen la sensibilidad a las condiciones iniciales, la dependencia de la elección de parámetros, la dificultad para determinar el número óptimo de agrupaciones y los desafíos con el manejo de datos de alta dimensión o ruidosos.
P. ¿De qué depende la calidad del resultado del clustering?
La calidad de los resultados de la agrupación depende de factores como la elección del algoritmo, la métrica de distancia, el número de agrupaciones, el método de inicialización, las técnicas de preprocesamiento de datos, las métricas de evaluación de las agrupaciones y el conocimiento del dominio. Estos elementos influyen colectivamente en la eficacia y precisión del resultado de la agrupación.