Desde la invención de las computadoras, la gente ha estado usando el término ' Datos ' para referirse a la información informática, ya sea transmitida o almacenada. Sin embargo, también existen datos en los tipos de órdenes. Los datos pueden ser números o textos escritos en una hoja de papel, en forma de bits y bytes almacenados en la memoria de dispositivos electrónicos, o hechos almacenados en la mente de una persona. A medida que el mundo comenzó a modernizarse, estos datos se convirtieron en un aspecto importante de la vida cotidiana de todos y varias implementaciones les permitieron almacenarlos de manera diferente.
Datos es una colección de hechos y cifras o un conjunto de valores o valores de un formato específico que se refiere a un único conjunto de valores de elementos. Luego, los elementos de datos se clasifican en subelementos, que es el grupo de elementos que no se conocen como la forma primaria simple del elemento.
Consideremos un ejemplo en el que el nombre de un empleado se puede dividir en tres subelementos: nombre, segundo nombre y apellido. Sin embargo, una identificación asignada a un empleado generalmente se considerará un solo elemento.
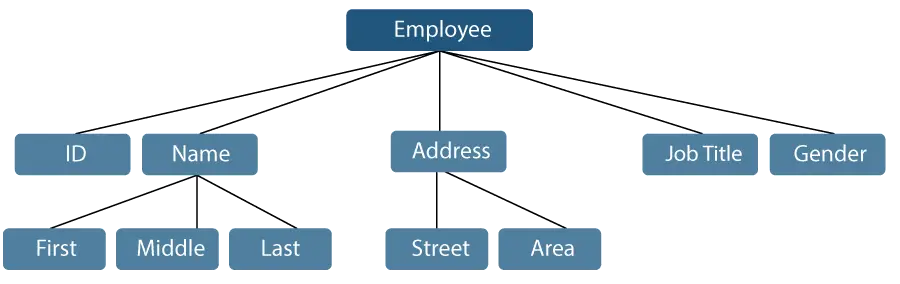
Figura 1: Representación de elementos de datos
En el ejemplo mencionado anteriormente, elementos como ID, edad, sexo, nombre, segundo nombre, apellido, calle, localidad, etc., son elementos de datos elementales. Por el contrario, el Nombre y la Dirección son elementos de datos de grupo.
¿Qué es la estructura de datos?
Estructura de datos es una rama de la Informática. El estudio de la estructura de datos nos permite comprender la organización de los datos y la gestión del flujo de datos para aumentar la eficiencia de cualquier proceso o programa. La estructura de datos es una forma particular de almacenar y organizar datos en la memoria de la computadora para que estos datos puedan recuperarse fácilmente y utilizarse de manera eficiente en el futuro cuando sea necesario. Los datos se pueden gestionar de varias formas, al igual que el modelo lógico o matemático para una organización específica de datos se conoce como estructura de datos.
El alcance de un modelo de datos particular depende de dos factores:
- Primero, debe cargarse lo suficiente en la estructura para reflejar la correlación definitiva de los datos con un objeto del mundo real.
- En segundo lugar, la formación debe ser tan sencilla que uno pueda adaptarse para procesar los datos de manera eficiente cuando sea necesario.
Algunos ejemplos de estructuras de datos son matrices, listas enlazadas, pilas, colas, árboles, etc. Las estructuras de datos se utilizan ampliamente en casi todos los aspectos de la informática, es decir, diseño de compiladores, sistemas operativos, gráficos, inteligencia artificial y muchos más.
Las estructuras de datos son la parte principal de muchos algoritmos informáticos, ya que permiten a los programadores gestionar los datos de forma eficaz. Desempeña un papel crucial en la mejora del rendimiento de un programa o software, ya que el objetivo principal del software es almacenar y recuperar los datos del usuario lo más rápido posible.
contiene pitón
Terminologías básicas relacionadas con estructuras de datos
Las estructuras de datos son los componentes básicos de cualquier software o programa. Seleccionar la estructura de datos adecuada para un programa es una tarea extremadamente desafiante para un programador.
Las siguientes son algunas terminologías fundamentales que se utilizan siempre que se trate de estructuras de datos:
| Atributos | IDENTIFICACIÓN | Nombre | Género | Título profesional |
|---|---|---|---|---|
| Valores | 1234 | Stacey M. Hill | Femenino | Desarrollador de software |
Entidades con atributos similares forman una Conjunto de entidades . Cada atributo de un conjunto de entidades tiene un rango de valores, el conjunto de todos los valores posibles que podrían asignarse al atributo específico.
El término 'información' a veces se utiliza para datos con atributos dados de datos significativos o procesados.
Comprender la necesidad de estructuras de datos
A medida que las aplicaciones se vuelven más complejas y la cantidad de datos aumenta cada día, lo que puede generar problemas con la búsqueda de datos, la velocidad de procesamiento, el manejo de múltiples solicitudes y muchos más. Las estructuras de datos admiten diferentes métodos para organizar, administrar y almacenar datos de manera eficiente. Con la ayuda de estructuras de datos, podemos recorrer fácilmente los elementos de datos. Las estructuras de datos proporcionan eficiencia, reutilización y abstracción.
¿Por qué deberíamos aprender estructuras de datos?
- Las estructuras de datos y los algoritmos son dos de los aspectos clave de la informática.
- Las estructuras de datos nos permiten organizar y almacenar datos, mientras que los algoritmos nos permiten procesar esos datos de manera significativa.
- Aprender estructuras de datos y algoritmos nos ayudará a convertirnos en mejores programadores.
- Podremos escribir código que sea más efectivo y confiable.
- También podremos resolver problemas de forma más rápida y eficaz.
Comprender los objetivos de las estructuras de datos
Las Estructuras de Datos satisfacen dos objetivos complementarios:
Comprender algunas características clave de las estructuras de datos
Algunas de las características importantes de las estructuras de datos son:
Clasificación de estructuras de datos
Una estructura de datos ofrece un conjunto estructurado de variables relacionadas entre sí de varias maneras. Constituye la base de una herramienta de programación que indica la relación entre los elementos de datos y permite a los programadores procesar los datos de manera eficiente.
Podemos clasificar las Estructuras de Datos en dos categorías:
- Estructura de datos primitiva
- Estructura de datos no primitiva
La siguiente figura muestra las diferentes clasificaciones de Estructuras de Datos.

Figura 2: Clasificaciones de estructuras de datos
Estructuras de datos primitivas
- Estas estructuras de datos pueden manipularse u operarse directamente mediante instrucciones a nivel de máquina.
- Tipos de datos básicos como Entero, flotante, carácter , y Booleano pertenecen a las estructuras de datos primitivas.
- Estos tipos de datos también se denominan Tipos de datos simples , ya que contienen caracteres que no se pueden dividir más
Estructuras de datos no primitivas
- Estas estructuras de datos no pueden manipularse ni operarse directamente mediante instrucciones a nivel de máquina.
- El objetivo de estas estructuras de datos es formar un conjunto de elementos de datos que sean homogéneo (mismo tipo de datos) o heterogéneo (diferentes tipos de datos).
- Según la estructura y disposición de los datos, podemos dividir estas estructuras de datos en dos subcategorías:
- Estructuras de datos lineales
- Estructuras de datos no lineales
Estructuras de datos lineales
Una estructura de datos que preserva una conexión lineal entre sus elementos de datos se conoce como estructura de datos lineal. La disposición de los datos se realiza de forma lineal, donde cada elemento consta de sucesores y predecesores, excepto el primer y el último elemento de datos. Sin embargo, esto no es necesariamente cierto en el caso de la memoria, ya que la disposición puede no ser secuencial.
Según la asignación de memoria, las estructuras de datos lineales se clasifican en dos tipos:
El Formación es el mejor ejemplo de estructura de datos estática, ya que tienen un tamaño fijo y sus datos se pueden modificar más adelante.
Listas enlazadas, pilas , y Cruz son ejemplos comunes de estructuras de datos dinámicas
Tipos de estructuras de datos lineales
La siguiente es la lista de estructuras de datos lineales que generalmente utilizamos:
1. matrices
Un Formación es una estructura de datos que se utiliza para recopilar múltiples elementos de datos del mismo tipo de datos en una variable. En lugar de almacenar múltiples valores del mismo tipo de datos en nombres de variables separados, podríamos almacenarlos todos juntos en una sola variable. Esta afirmación no implica que tendremos que unir todos los valores del mismo tipo de datos en cualquier programa en una matriz de ese tipo de datos. Pero a menudo habrá ocasiones en las que algunas variables específicas del mismo tipo de datos estén relacionadas entre sí de una manera apropiada para una matriz.
Una matriz es una lista de elementos donde cada elemento tiene un lugar único en la lista. Los elementos de datos de la matriz comparten el mismo nombre de variable; sin embargo, cada uno lleva un número de índice diferente llamado subíndice. Podemos acceder a cualquier elemento de datos de la lista con la ayuda de su ubicación en la lista. Por lo tanto, la característica clave que hay que comprender de las matrices es que los datos se almacenan en ubicaciones de memoria contiguas, lo que permite a los usuarios recorrer los elementos de datos de la matriz utilizando sus respectivos índices.
freddie mercurio nacido

Figura 3. Una matriz
Los arrays se pueden clasificar en diferentes tipos:
Algunas aplicaciones de matriz:
- Podemos almacenar una lista de elementos de datos que pertenecen al mismo tipo de datos.
- La matriz actúa como almacenamiento auxiliar para otras estructuras de datos.
- La matriz también ayuda a almacenar elementos de datos de un árbol binario de recuento fijo.
- Array también actúa como almacenamiento de matrices.
2. Listas enlazadas
A Lista enlazada es otro ejemplo de una estructura de datos lineal utilizada para almacenar una colección de elementos de datos de forma dinámica. Los elementos de datos en esta estructura de datos están representados por los nodos, conectados mediante enlaces o punteros. Cada nodo contiene dos campos, el campo de información consta de los datos reales y el campo de puntero consta de la dirección de los nodos siguientes en la lista. El puntero del último nodo de la lista enlazada consta de un puntero nulo, ya que no apunta a nada. A diferencia de las matrices, el usuario puede ajustar dinámicamente el tamaño de una lista vinculada según los requisitos.

Figura 4. Una lista enlazada
Las Listas Enlazadas se pueden clasificar en diferentes tipos:
Algunas aplicaciones de listas enlazadas:
- Las Listas Enlazadas nos ayudan a implementar pilas, colas, árboles binarios y gráficos de tamaño predefinido.
- También podemos implementar la función del sistema operativo para la gestión dinámica de la memoria.
- Las listas enlazadas también permiten la implementación polinomial para operaciones matemáticas.
- Podemos utilizar la Lista Vinculada Circular para implementar sistemas operativos o funciones de aplicaciones que realizan tareas por turnos.
- La lista enlazada circular también es útil en una presentación de diapositivas donde un usuario debe volver a la primera diapositiva después de presentar la última.
- La lista doblemente enlazada se utiliza para implementar botones de avance y retroceso en un navegador para avanzar y retroceder en las páginas abiertas de un sitio web.
3. Pilas
A Pila es una estructura de datos lineal que sigue la LIFO Principio (Último en entrar, primero en salir) que permite operaciones como inserción y eliminación desde un extremo de la pila, es decir, Top. Las pilas se pueden implementar con la ayuda de memoria contigua, una matriz, y memoria no contigua, una lista vinculada. Ejemplos de Stacks en la vida real son montones de libros, una baraja de cartas, montones de dinero y muchos más.

Figura 5. Un ejemplo de pila de la vida real
La figura anterior representa el ejemplo de la vida real de una Pila donde las operaciones se realizan desde un solo extremo, como la inserción y extracción de libros nuevos desde la parte superior de la Pila. Implica que la inserción y eliminación en la Pila solo se puede realizar desde la parte superior de la Pila. Solo podemos acceder a las cimas del Stack en un momento dado.
Las operaciones principales en la pila son las siguientes:
trimestre en el negocio

Figura 6. Un montón
Algunas aplicaciones de las pilas:
- La pila se utiliza como estructura de almacenamiento temporal para operaciones recursivas.
- La pila también se utiliza como estructura de almacenamiento auxiliar para llamadas a funciones, operaciones anidadas y funciones diferidas/pospuestas.
- Podemos gestionar llamadas a funciones utilizando Stacks.
- Las pilas también se utilizan para evaluar expresiones aritméticas en diferentes lenguajes de programación.
- Las pilas también son útiles para convertir expresiones infijas en expresiones postfijas.
- Las pilas nos permiten comprobar la sintaxis de la expresión en el entorno de programación.
- Podemos unir paréntesis usando Stacks.
- Las pilas se pueden utilizar para invertir una cadena.
- Las pilas son útiles para resolver problemas basados en el retroceso.
- Podemos usar Stacks en la búsqueda en profundidad en el recorrido de gráficos y árboles.
- Las pilas también se utilizan en funciones del sistema operativo.
- Las pilas también se utilizan en las funciones UNDO y REDO en una edición.
4. Colas
A Cola Es una estructura de datos lineal similar a una pila con algunas limitaciones en la inserción y eliminación de elementos. La inserción de un elemento en una Cola se realiza por un extremo y la eliminación se realiza por el otro extremo o el opuesto. Por lo tanto, podemos concluir que la estructura de datos de la cola sigue el principio FIFO (primero en entrar, primero en salir) para manipular los elementos de datos. La implementación de colas se puede realizar mediante matrices, listas vinculadas o pilas. Algunos ejemplos de colas de la vida real son una fila en el mostrador de boletos, una escalera mecánica, un lavado de autos y muchos más.

Figura 7. Un ejemplo de cola de la vida real
La imagen de arriba es una ilustración de la vida real de un mostrador de entradas de cine que puede ayudarnos a comprender la cola donde siempre se atiende primero al cliente que llega primero. El cliente que llegue último, sin duda, será atendido el último. Ambos extremos de la cola están abiertos y pueden ejecutar diferentes operaciones. Otro ejemplo es una línea de patio de comidas donde el cliente se inserta desde la parte trasera mientras que el cliente se retira por la parte delantera después de brindar el servicio que solicitó.
Las siguientes son las operaciones principales de la cola:
np significa

Figura 8. A Queue
Algunas aplicaciones de colas:
- Las colas se utilizan generalmente en la operación de búsqueda amplia en Graphs.
- Las colas también se utilizan en las operaciones del programador de trabajos de los sistemas operativos, como una cola de búfer de teclado para almacenar las teclas presionadas por los usuarios y una cola de búfer de impresión para almacenar los documentos impresos por la impresora.
- Las colas son responsables de la programación de la CPU, la programación de trabajos y la programación del disco.
- Las colas prioritarias se utilizan en operaciones de descarga de archivos en un navegador.
- Las colas también se utilizan para transferir datos entre dispositivos periféricos y la CPU.
- Las colas también son responsables de manejar las interrupciones generadas por las Aplicaciones de Usuario para la CPU.
Estructuras de datos no lineales
Las estructuras de datos no lineales son estructuras de datos donde los elementos de datos no están organizados en orden secuencial. En este caso, la inserción y eliminación de datos no es factible de forma lineal. Existe una relación jerárquica entre los elementos de datos individuales.
Tipos de estructuras de datos no lineales
La siguiente es la lista de estructuras de datos no lineales que generalmente utilizamos:
1. árboles
Un árbol es una estructura de datos no lineal y una jerarquía que contiene una colección de nodos de modo que cada nodo del árbol almacena un valor y una lista de referencias a otros nodos (los 'hijos').
La estructura de datos de árbol es un método especializado para organizar y recopilar datos en la computadora para utilizarlos de manera más efectiva. Contiene un nodo central, nodos estructurales y subnodos conectados mediante bordes. También podemos decir que la estructura de datos del árbol consta de raíces, ramas y hojas conectadas.

Figura 9. Un árbol
Los árboles se pueden clasificar en diferentes tipos:
Algunas aplicaciones de los árboles:
- Los árboles implementan estructuras jerárquicas en sistemas informáticos como directorios y sistemas de archivos.
- Los árboles también se utilizan para implementar la estructura de navegación de un sitio web.
- Podemos generar código como el código de Huffman usando Trees.
- Los árboles también son útiles para la toma de decisiones en aplicaciones de juegos.
- Los árboles son responsables de implementar colas de prioridad para funciones de programación del sistema operativo basadas en prioridades.
- Los árboles también son responsables de analizar expresiones y declaraciones en los compiladores de diferentes lenguajes de programación.
- Podemos utilizar árboles para almacenar claves de datos para la indexación del sistema de gestión de bases de datos (DBMS).
- Spanning Trees nos permite encaminar decisiones en Redes de Computación y Comunicaciones.
- Los árboles también se utilizan en el algoritmo de búsqueda de rutas implementado en aplicaciones de inteligencia artificial (IA), robótica y videojuegos.
2. Gráficos
Un gráfico es otro ejemplo de una estructura de datos no lineal que comprende un número finito de nodos o vértices y los bordes que los conectan. Los gráficos se utilizan para abordar problemas del mundo real en los que denota el área problemática como una red, como redes sociales, redes de circuitos y redes telefónicas. Por ejemplo, los nodos o vértices de un Graph pueden representar a un solo usuario en una red telefónica, mientras que los bordes representan el enlace entre ellos a través del teléfono.
La estructura de datos del gráfico, G, se considera una estructura matemática compuesta por un conjunto de vértices, V y un conjunto de aristas, E, como se muestra a continuación:
GRAMO = (V,E)

Figura 10. Un gráfico
La figura anterior representa un gráfico que tiene siete vértices A, B, C, D, E, F, G y diez aristas [A, B], [A, C], [B, C], [B, D], [B, E], [C, D], [D, E], [D, F], [E, F] y [E, G].
Dependiendo de la posición de los vértices y aristas, los Gráficos se pueden clasificar en diferentes tipos:
mapa iterativo java
Algunas aplicaciones de gráficos:
- Los gráficos nos ayudan a representar rutas y redes en aplicaciones de transporte, viajes y comunicaciones.
- Los gráficos se utilizan para mostrar rutas en GPS.
- Los gráficos también nos ayudan a representar las interconexiones en redes sociales y otras aplicaciones basadas en redes.
- Los gráficos se utilizan en aplicaciones de mapeo.
- Los gráficos son responsables de la representación de las preferencias del usuario en aplicaciones de comercio electrónico.
- Los gráficos también se utilizan en las redes de servicios públicos para identificar los problemas que plantean las corporaciones locales o municipales.
- Los gráficos también ayudan a gestionar la utilización y disponibilidad de los recursos en una organización.
- Los gráficos también se utilizan para crear mapas de enlaces de documentos de los sitios web con el fin de mostrar la conectividad entre las páginas a través de hipervínculos.
- Los gráficos también se utilizan en movimientos robóticos y redes neuronales.
Operaciones básicas de estructuras de datos.
En la siguiente sección, discutiremos los diferentes tipos de operaciones que podemos realizar para manipular datos en cada estructura de datos:
- Tiempo de compilación
- tiempo de ejecución
Por ejemplo, el malloc() La función se utiliza en lenguaje C para crear una estructura de datos.
Comprender el tipo de datos abstractos
Según el Instituto Nacional de Estándares y Tecnología (NIST) , una estructura de datos es una disposición de información, generalmente en la memoria, para una mejor eficiencia del algoritmo. Las estructuras de datos incluyen listas vinculadas, pilas, colas, árboles y diccionarios. También podrían ser una entidad teórica, como el nombre y la dirección de una persona.
De la definición mencionada anteriormente, podemos concluir que las operaciones en la estructura de datos incluyen:
- Un alto nivel de abstracciones como agregar o eliminar un elemento de una lista.
- Buscar y ordenar un elemento en una lista.
- Acceder al elemento de mayor prioridad en una lista.
Siempre que la estructura de datos realiza tales operaciones, se conoce como Tipo de datos abstractos (ADT) .
Podemos definirlo como un conjunto de elementos de datos junto con las operaciones sobre los datos. El término 'abstracto' se refiere al hecho de que los datos y las operaciones fundamentales definidas en ellos se estudian independientemente de su implementación. Incluye lo que podemos hacer con los datos, no cómo podemos hacerlo.
Una implementación de ADI contiene una estructura de almacenamiento para almacenar los elementos de datos y algoritmos para la operación fundamental. Todas las estructuras de datos, como una matriz, una lista vinculada, una cola, una pila, etc., son ejemplos de ADT.
Comprender las ventajas de utilizar ADT
En el mundo real, los programas evolucionan como consecuencia de nuevas restricciones o requisitos, por lo que modificar un programa generalmente requiere un cambio en una o varias estructuras de datos. Por ejemplo, supongamos que queremos insertar un nuevo campo en el registro de un empleado para realizar un seguimiento de más detalles sobre cada empleado. En ese caso, podemos mejorar la eficiencia del programa reemplazando un Array con una estructura Enlazada. En tal situación, no es adecuado reescribir todos los procedimientos que utilizan la estructura modificada. Por tanto, una mejor alternativa es separar una estructura de datos de su información de implementación. Este es el principio detrás del uso de tipos de datos abstractos (ADT).
Algunas aplicaciones de estructuras de datos
Las siguientes son algunas aplicaciones de las estructuras de datos:
- Las estructuras de datos ayudan en la organización de los datos en la memoria de una computadora.
- Las estructuras de datos también ayudan a representar la información en las bases de datos.
- Las estructuras de datos permiten la implementación de algoritmos para buscar a través de datos (por ejemplo, motor de búsqueda).
- Podemos utilizar las estructuras de datos para implementar algoritmos para manipular datos (por ejemplo, procesadores de texto).
- También podemos implementar algoritmos para analizar datos utilizando estructuras de datos (por ejemplo, mineros de datos).
- Las estructuras de datos admiten algoritmos para generar datos (por ejemplo, un generador de números aleatorios).
- Las estructuras de datos también admiten algoritmos para comprimir y descomprimir los datos (por ejemplo, una utilidad zip).
- También podemos utilizar estructuras de datos para implementar algoritmos para cifrar y descifrar los datos (por ejemplo, un sistema de seguridad).
- Con la ayuda de estructuras de datos, podemos crear software que pueda administrar archivos y directorios (por ejemplo, un administrador de archivos).
- También podemos desarrollar software que pueda representar gráficos utilizando estructuras de datos. (Por ejemplo, un navegador web o un software de renderizado 3D).
Aparte de estas, como se mencionó anteriormente, existen muchas otras aplicaciones de estructuras de datos que pueden ayudarnos a construir cualquier software que deseemos.