Las hojas de Excel son muy instintivas y fáciles de usar, lo que las hace ideales para manipular grandes conjuntos de datos incluso para personas menos técnicas. Si está buscando lugares para aprender a manipular y automatizar cosas en archivos de Excel usando Pitón , no busque más. Estás en el lugar correcto.
En este artículo aprenderás a utilizar pandas para trabajar con hojas de cálculo de Excel. En este artículo aprenderemos sobre:
- Leer Archivo Excel usando pandas en python
- Instalación e importación de Pandas
- Leer varias hojas de Excel usando Pandas
- Aplicación de diferentes funciones de Pandas
Lectura de archivos de Excel usando Pandas en Python
Instalación de pandas
Para instalar Pandas en Python, podemos usar el siguiente comando en el símbolo del sistema:
pip install pandas>
Para instalar Pandas en Anaconda, podemos usar el siguiente comando en Anaconda Terminal:
conda install pandas>
Importar pandas
En primer lugar, necesitamos importar el módulo Pandas, lo cual se puede hacer ejecutando el comando:
Python3
import> pandas as pd> |
>
>
Fichero de entrada: Supongamos que el archivo de Excel se ve así
Hoja 1:

Hoja 1
Hoja 2:
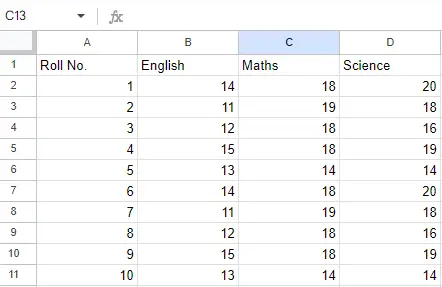
Hoja 2
Ahora podemos importar el archivo de Excel usando la función read_excel en Pandas para leer el archivo de Excel usando Pandas en Python. La segunda declaración lee los datos de Excel y los almacena en un marco de datos de pandas que está representado por la variable newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Producción:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Cargando varias hojas usando el método Concat()
Si hay varias hojas en el libro de Excel, el comando importará datos de la primera hoja. Para crear un marco de datos con todas las hojas del libro, el método más sencillo es crear diferentes marcos de datos por separado y luego concatenarlos. El método read_excel toma el argumento nombre_hoja e index_col donde podemos especificar la hoja de la que debe estar hecho el marco y index_col especifica la columna del título, como se muestra a continuación:
Ejemplo:
La tercera afirmación concatena ambas hojas. Ahora, para verificar todo el marco de datos, simplemente podemos ejecutar el siguiente comando:
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Producción:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Métodos Head() y Tail() en Pandas
Para ver 5 columnas desde la parte superior e inferior del marco de datos, podemos ejecutar el comando. Este cabeza() y cola() El método también toma argumentos como números para mostrar el número de columnas.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Producción:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Método forma()
El método forma() se puede utilizar para ver el número de filas y columnas en el marco de datos de la siguiente manera:
Python3
convertir fecha a cadena
newData.shape> |
>
>
Producción:
(20, 3)>
Método sort_values() en Pandas
Si alguna columna contiene datos numéricos, podemos ordenar esa columna usando el ordenar_valores() método en pandas de la siguiente manera:
Python3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Ahora, supongamos que queremos los 5 valores principales de la columna ordenada, podemos usar el método head() aquí:
Python3
sorted_column.head(>5>)> |
>
>
Producción:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Podemos hacer eso con cualquier columna numérica del marco de datos como se muestra a continuación:
Python3
newData[>'Maths'>].head()> |
>
>
Producción:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Método Pandas Describe()
Ahora supongamos que nuestros datos son en su mayoría numéricos. Podemos obtener información estadística como media, máximo, mínimo, etc. sobre el marco de datos utilizando el describir() método como se muestra a continuación:
Python3
newData.describe()> |
>
>
Producción:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Esto también se puede hacer por separado para todas las columnas numéricas usando el siguiente comando:
Python3
newData[>'English'>].mean()> |
>
>
Producción:
14.3>
También se puede calcular otra información estadística utilizando los métodos respectivos. Al igual que en Excel, también se pueden aplicar fórmulas y crear columnas calculadas de la siguiente manera:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
cuadro de lista html
Producción:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Después de operar con los datos en el marco de datos, podemos exportar los datos nuevamente a un archivo de Excel usando el método to_excel. Para esto, necesitamos especificar un archivo Excel de salida donde se escribirán los datos transformados, como se muestra a continuación:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Producción:
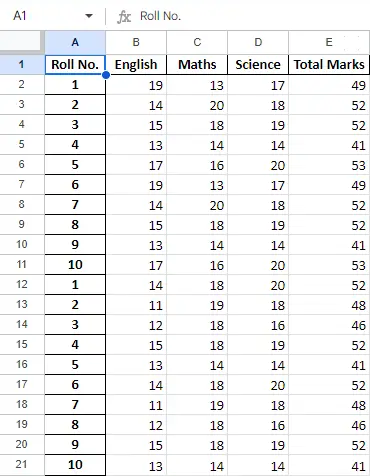
Hoja final