La búsqueda desinformada es una clase de algoritmos de búsqueda de propósito general que opera mediante fuerza bruta. Los algoritmos de búsqueda desinformados no tienen información adicional sobre el estado o el espacio de búsqueda aparte de cómo atravesar el árbol, por lo que también se denomina búsqueda ciega.
A continuación se detallan los distintos tipos de algoritmos de búsqueda desinformados:
1. Búsqueda en amplitud:
- La búsqueda en amplitud es la estrategia de búsqueda más común para recorrer un árbol o gráfico. Este algoritmo busca a lo ancho en un árbol o gráfico, por lo que se llama búsqueda en amplitud.
- El algoritmo BFS comienza a buscar desde el nodo raíz del árbol y expande todos los nodos sucesores en el nivel actual antes de pasar a los nodos del siguiente nivel.
- El algoritmo de búsqueda en amplitud es un ejemplo de un algoritmo de búsqueda de gráficos generales.
- Búsqueda en amplitud implementada utilizando la estructura de datos de cola FIFO.
Ventajas:
- BFS proporcionará una solución si existe alguna.
- Si hay más de una solución para un problema determinado, BFS proporcionará la solución mínima que requiera la menor cantidad de pasos.
Desventajas:
- Requiere mucha memoria ya que cada nivel del árbol debe guardarse en la memoria para expandir el siguiente nivel.
- BFS necesita mucho tiempo si la solución está lejos del nodo raíz.
Ejemplo:
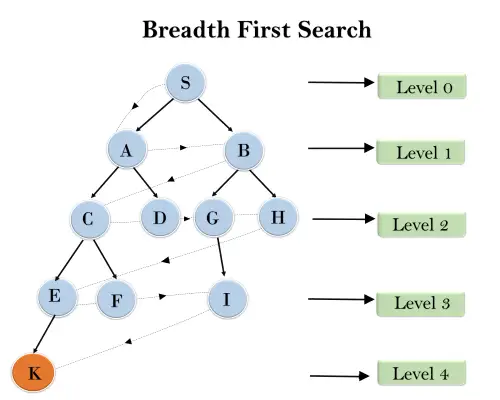
En la siguiente estructura de árbol, hemos mostrado el recorrido del árbol usando el algoritmo BFS desde el nodo raíz S hasta el nodo objetivo K. El algoritmo de búsqueda BFS recorre en capas, por lo que seguirá la ruta que se muestra con la flecha punteada y la El camino recorrido será:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
Complejidad del tiempo: La complejidad temporal del algoritmo BFS se puede obtener mediante la cantidad de nodos atravesados en BFS hasta el nodo más superficial. Donde d = profundidad de la solución más superficial y b es un nodo en cada estado.
T (b) = 1+b2+b3+.......+bd= O (bd)
Complejidad espacial: La complejidad espacial del algoritmo BFS viene dada por el tamaño de la memoria de la frontera, que es O(bd).
Lo completo: BFS está completo, lo que significa que si el nodo objetivo menos profundo tiene una profundidad finita, entonces BFS encontrará una solución.
Optimidad: BFS es óptimo si el costo de la ruta es una función no decreciente de la profundidad del nodo.
2. Búsqueda en profundidad
- La búsqueda en profundidad es un algoritmo recursivo para atravesar una estructura de datos de árbol o gráfico.
- Se llama búsqueda en profundidad porque comienza desde el nodo raíz y sigue cada ruta hasta su nodo de mayor profundidad antes de pasar a la siguiente ruta.
- DFS utiliza una estructura de datos de pila para su implementación.
- El proceso del algoritmo DFS es similar al algoritmo BFS.
Nota: El retroceso es una técnica algorítmica para encontrar todas las soluciones posibles mediante la recursividad.
Ventaja:
- DFS requiere muy menos memoria ya que solo necesita almacenar una pila de nodos en la ruta desde el nodo raíz hasta el nodo actual.
- Se necesita menos tiempo para llegar al nodo objetivo que el algoritmo BFS (si recorre el camino correcto).
Desventaja:
- Existe la posibilidad de que muchos estados sigan repitiéndose y no hay garantía de encontrar la solución.
- El algoritmo DFS realiza búsquedas profundas y, en algún momento, puede llegar al bucle infinito.
Ejemplo:
En el siguiente árbol de búsqueda, hemos mostrado el flujo de búsqueda en profundidad y seguirá el orden siguiente:
Nodo raíz--->Nodo izquierdo ----> nodo derecho.
Comenzará a buscar desde el nodo raíz S y atravesará A, luego B, luego D y E, después de atravesar E, retrocederá en el árbol ya que E no tiene otro sucesor y aún así no se encuentra el nodo objetivo. Después de retroceder, atravesará el nodo C y luego G, y aquí terminará cuando encontró el nodo objetivo.

Lo completo: El algoritmo de búsqueda DFS se completa dentro de un espacio de estados finito, ya que expandirá cada nodo dentro de un árbol de búsqueda limitado.
Complejidad del tiempo: La complejidad temporal de DFS será equivalente al nodo atravesado por el algoritmo. Está dado por:
T(norte)= 1+ norte2+ norte3+.........+ nortemetro=O(nmetro)
caja del interruptor java
Donde, m = profundidad máxima de cualquier nodo y esto puede ser mucho mayor que d (profundidad de solución más superficial)
Complejidad espacial: El algoritmo DFS necesita almacenar solo una ruta única desde el nodo raíz, por lo tanto, la complejidad espacial de DFS es equivalente al tamaño del conjunto marginal, que es Acerca de .
Óptimo: El algoritmo de búsqueda DFS no es óptimo, ya que puede generar una gran cantidad de pasos o un alto costo para llegar al nodo objetivo.
3. Algoritmo de búsqueda de profundidad limitada:
Un algoritmo de búsqueda de profundidad limitada es similar a una búsqueda de profundidad limitada con un límite predeterminado. La búsqueda de profundidad limitada puede resolver el inconveniente del camino infinito en la búsqueda de profundidad primero. En este algoritmo, el nodo en el límite de profundidad se tratará como si no tuviera nodos sucesores más.
La búsqueda de profundidad limitada se puede finalizar con dos condiciones de falla:
- Valor de falla estándar: Indica que el problema no tiene solución.
- Valor de corte de falla: no define ninguna solución para el problema dentro de un límite de profundidad determinado.
Ventajas:
La búsqueda con profundidad limitada es eficiente en cuanto a memoria.
Desventajas:
- La búsqueda de profundidad limitada también tiene la desventaja de ser incompleta.
- Puede que no sea óptimo si el problema tiene más de una solución.
Ejemplo:

Lo completo: El algoritmo de búsqueda DLS está completo si la solución está por encima del límite de profundidad.
Complejidad del tiempo: La complejidad temporal del algoritmo DLS es Transmisión exteriorℓ) .
Complejidad espacial: La complejidad espacial del algoritmo DLS es O (b�ℓ) .
Óptimo: La búsqueda de profundidad limitada puede verse como un caso especial de DFS y tampoco es óptima incluso si ℓ>d.
4. Algoritmo de búsqueda de costo uniforme:
La búsqueda de costo uniforme es un algoritmo de búsqueda que se utiliza para recorrer un árbol o gráfico ponderado. Este algoritmo entra en juego cuando hay disponible un costo diferente para cada ventaja. El objetivo principal de la búsqueda de costo uniforme es encontrar una ruta hacia el nodo objetivo que tenga el costo acumulado más bajo. La búsqueda de costo uniforme expande los nodos según sus costos de ruta desde el nodo raíz. Se puede utilizar para resolver cualquier gráfico/árbol donde se demande el costo óptimo. La cola de prioridad implementa un algoritmo de búsqueda de costo uniforme. Da máxima prioridad al menor coste acumulativo. La búsqueda de costo uniforme es equivalente al algoritmo BFS si el costo de la ruta de todos los bordes es el mismo.
Ventajas:
- La búsqueda de costos uniformes es óptima porque en cada estado se elige el camino con el menor costo.
Desventajas:
- No le importa la cantidad de pasos involucrados en la búsqueda y solo le preocupa el costo de la ruta. Por lo que este algoritmo puede quedar atrapado en un bucle infinito.
Ejemplo:

Lo completo:
La búsqueda de costos uniformes está completa; por ejemplo, si hay una solución, UCS la encontrará.
Complejidad del tiempo:
Sea C* es el costo de la solución óptima , y mi es cada paso para acercarse al nodo objetivo. Entonces el número de pasos es = C*/ε+1. Aquí hemos tomado +1, ya que comenzamos desde el estado 0 y terminamos en C*/ε.
Por lo tanto, la complejidad temporal del peor de los casos de la búsqueda de costo uniforme es Transmisión exterior1 + [C*/e])/ .
Complejidad espacial:
La misma lógica se aplica a la complejidad espacial, por lo que la complejidad espacial en el peor de los casos de la búsqueda de costo uniforme es Transmisión exterior1 + [C*/e]) .
Óptimo:
La búsqueda de costo uniforme siempre es óptima ya que solo selecciona una ruta con el costo de ruta más bajo.
5. Búsqueda iterativa de profundización primero en profundidad:
El algoritmo de profundización iterativo es una combinación de algoritmos DFS y BFS. Este algoritmo de búsqueda descubre el mejor límite de profundidad y lo hace aumentando gradualmente el límite hasta encontrar un objetivo.
Este algoritmo realiza una búsqueda en profundidad hasta un cierto 'límite de profundidad' y sigue aumentando el límite de profundidad después de cada iteración hasta que se encuentra el nodo objetivo.
Este algoritmo de búsqueda combina los beneficios de la búsqueda rápida de la búsqueda en amplitud y la eficiencia de la memoria de la búsqueda en profundidad.
El algoritmo de búsqueda iterativa es útil para búsquedas no informadas cuando el espacio de búsqueda es grande y se desconoce la profundidad del nodo objetivo.
Ventajas:
- Combina los beneficios del algoritmo de búsqueda BFS y DFS en términos de búsqueda rápida y eficiencia de memoria.
Desventajas:
- El principal inconveniente de IDDFS es que repite todo el trabajo de la fase anterior.
Ejemplo:
La siguiente estructura de árbol muestra la búsqueda iterativa de profundización primero en profundidad. El algoritmo IDDFS realiza varias iteraciones hasta que no encuentra el nodo objetivo. La iteración realizada por el algoritmo viene dada por:

1.ª iteración-----> A
2da iteración----> A, B, C
Tercera iteración------>A, B, D, E, C, F, G
4ª iteración------>A, B, D, H, I, E, C, F, K, G
En la cuarta iteración, el algoritmo encontrará el nodo objetivo.
Lo completo:
Este algoritmo está completo si el factor de ramificación es finito.
Complejidad del tiempo:
Supongamos que b es el factor de ramificación y la profundidad es d, entonces la complejidad temporal en el peor de los casos es Transmisión exteriord) .
Complejidad espacial:
La complejidad espacial de IDDFS será O(bd) .
para bucle en c
Óptimo:
El algoritmo IDDFS es óptimo si el costo de la ruta es una función no decreciente de la profundidad del nodo.
6. Algoritmo de búsqueda bidireccional:
El algoritmo de búsqueda bidireccional ejecuta dos búsquedas simultáneas, una desde el estado inicial denominada búsqueda hacia adelante y otra desde el nodo objetivo denominada búsqueda hacia atrás, para encontrar el nodo objetivo. La búsqueda bidireccional reemplaza un único gráfico de búsqueda con dos pequeños subgrafos en los que uno comienza la búsqueda desde un vértice inicial y el otro comienza desde el vértice objetivo. La búsqueda se detiene cuando estos dos gráficos se cruzan.
La búsqueda bidireccional puede utilizar técnicas de búsqueda como BFS, DFS, DLS, etc.
Ventajas:
- La búsqueda bidireccional es rápida.
- La búsqueda bidireccional requiere menos memoria
Desventajas:
- La implementación del árbol de búsqueda bidireccional es difícil.
Ejemplo:
En el siguiente árbol de búsqueda, se aplica un algoritmo de búsqueda bidireccional. Este algoritmo divide un gráfico/árbol en dos subgráficos. Comienza a atravesar desde el nodo 1 en dirección hacia adelante y comienza desde el nodo objetivo 16 en dirección hacia atrás.
El algoritmo termina en el nodo 9 donde se encuentran dos búsquedas.

Lo completo: La búsqueda bidireccional es completa si utilizamos BFS en ambas búsquedas.
Complejidad del tiempo: La complejidad temporal de la búsqueda bidireccional utilizando BFS es Transmisión exteriord) .
Complejidad espacial: La complejidad espacial de la búsqueda bidireccional es Transmisión exteriord) .
Óptimo: La búsqueda bidireccional es óptima.