En el sistema operativo, teníamos que darle la entrada a la CPU, y la CPU ejecuta las instrucciones y finalmente da la salida. Pero había un problema con este enfoque. En una situación normal, tenemos que lidiar con muchos procesos y sabemos que el tiempo que toma la operación de E/S es muy grande en comparación con el tiempo que toma la CPU para ejecutar las instrucciones. Entonces, en el enfoque anterior, un proceso proporcionaría la entrada con la ayuda de un dispositivo de entrada y, durante este tiempo, la CPU está en estado inactivo.
comando de linux para zip
Luego, la CPU ejecuta la instrucción y la salida se envía nuevamente a algún dispositivo de salida y, en este momento, la CPU también está en un estado inactivo. Después de mostrar el resultado, el siguiente proceso comienza su ejecución. Entonces, la mayor parte del tiempo la CPU está inactiva, que es la peor condición que podemos tener en los Sistemas Operativos. Aquí entra en juego el concepto de Spooling.
¿Qué es el spooling?
La cola de impresión es un proceso en el que los datos se conservan temporalmente para ser utilizados y ejecutados por un dispositivo, programa o sistema. Los datos se envían y almacenan en la memoria u otro almacenamiento volátil hasta que el programa o la computadora solicita su ejecución.
CARRETE es un acrónimo de operaciones periféricas simultáneas en línea . Generalmente, el spool se mantiene en la memoria física, los buffers o las interrupciones específicas del dispositivo de E/S de la computadora. El spool se procesa en orden ascendente, funcionando según un algoritmo FIFO (primero en entrar, primero en salir).
El spooling se refiere a poner datos de varios trabajos de E/S en un búfer. Este búfer es un área especial en la memoria o en el disco duro a la que pueden acceder los dispositivos de E/S. Un sistema operativo realiza las siguientes actividades relacionadas con el entorno distribuido:
- Maneja la cola de datos de dispositivos de E/S, ya que los dispositivos tienen diferentes velocidades de acceso a datos.
- Mantiene el búfer de cola, que proporciona una estación de espera donde los datos pueden descansar mientras el dispositivo más lento se pone al día.
- Mantiene el cálculo paralelo debido al proceso de cola, ya que una computadora puede realizar E/S en orden paralelo. Es posible hacer que la computadora lea datos de una cinta, escriba datos en un disco y escriba en una impresora de cinta mientras realiza su tarea informática.
Cómo funciona el spooling en el sistema operativo
En un sistema operativo, el spooling funciona en los siguientes pasos, como:
- El spooling implica la creación de un búfer llamado SPOOL, que se utiliza para retener trabajos y datos hasta que el dispositivo en el que se crea el SPOOL esté listo para utilizar y ejecutar ese trabajo u operar con los datos.
- Cuando un dispositivo más rápido envía datos a un dispositivo más lento para realizar alguna operación, utiliza cualquier memoria secundaria conectada como búfer SPOOL. Estos datos se mantienen en el SPOOL hasta que el dispositivo más lento esté listo para operar con estos datos. Cuando el dispositivo más lento está listo, los datos del SPOOL se cargan en la memoria principal para las operaciones requeridas.
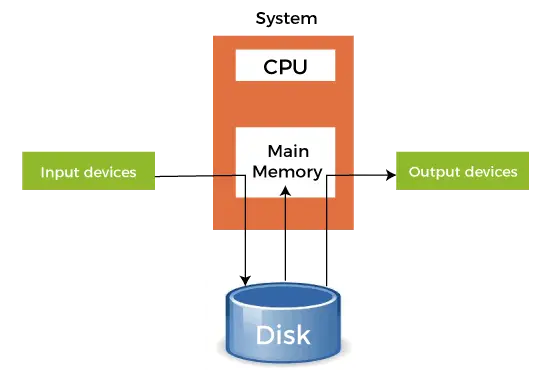
- El spooling considera toda la memoria secundaria como un enorme búfer que puede almacenar muchos trabajos y datos para muchas operaciones. La ventaja de Spooling es que puede crear una cola de trabajos que se ejecutan en orden FIFO para ejecutar los trabajos uno por uno.
- Un dispositivo puede conectarse a muchos dispositivos de entrada, lo que puede requerir alguna operación con sus datos. Por lo tanto, todos estos dispositivos de entrada pueden colocar sus datos en la memoria secundaria (SPOOL), que luego el dispositivo puede ejecutar uno por uno. Esto asegurará que la CPU no esté inactiva en ningún momento. Entonces, podemos decir que Spooling es una combinación de almacenamiento en búfer y cola.
- Después de que la CPU genera alguna salida, esta salida se guarda primero en la memoria principal. Esta salida se transfiere a la memoria secundaria desde la memoria principal, y desde allí, la salida se envía a los respectivos dispositivos de salida.

Ejemplo de cola
El mayor ejemplo de Spooling es impresión . Los documentos que se van a imprimir se almacenan en el SPOOL y luego se agregan a la cola para imprimir. Durante este tiempo, muchos procesos pueden realizar sus operaciones y utilizar la CPU sin esperar mientras la impresora ejecuta el proceso de impresión en los documentos uno por uno.

También se pueden agregar muchas funciones al proceso de impresión Spooling, como establecer prioridades o notificar cuando se ha completado el proceso de impresión o seleccionar los diferentes tipos de papel para imprimir según la elección del usuario.
Ventajas del spooling
Estas son las siguientes ventajas del spooling en un sistema operativo, como:
- No importa el número de dispositivos de E/S u operaciones. Muchos dispositivos de E/S pueden funcionar juntos simultáneamente sin interferencias ni interrupciones entre sí.
- En el spooling, no hay interacción entre los dispositivos de E/S y la CPU. Eso significa que no es necesario que la CPU espere a que se realicen las operaciones de E/S. Estas operaciones tardan mucho en terminar de ejecutarse, por lo que la CPU no esperará a que finalicen.
- La CPU en estado inactivo no se considera muy eficiente. La mayoría de los protocolos se crean para utilizar la CPU de manera eficiente en el mínimo de tiempo. En el spooling, la CPU se mantiene ocupada la mayor parte del tiempo y solo pasa al estado inactivo cuando la cola se agota. Entonces, todas las tareas se agregan a la cola y la CPU finalizará todas esas tareas y luego entrará en el estado inactivo.
- Permite que las aplicaciones se ejecuten a la velocidad de la CPU mientras operan los dispositivos de E/S a sus respectivas velocidades máximas.
Desventajas del spooling
En un sistema operativo, el spooling tiene las siguientes desventajas, como por ejemplo:
- El spooling requiere una gran cantidad de almacenamiento dependiendo de la cantidad de solicitudes realizadas por la entrada y la cantidad de dispositivos de entrada conectados.
- Debido a que el SPOOL se crea en el almacenamiento secundario, tener muchos dispositivos de entrada funcionando simultáneamente puede ocupar mucho espacio en el almacenamiento secundario y, por lo tanto, aumentar el tráfico del disco. Esto hace que el disco se vuelva cada vez más lento a medida que el tráfico aumenta cada vez más.
- La cola de impresión se utiliza para copiar y ejecutar datos desde un dispositivo más lento a un dispositivo más rápido. El dispositivo más lento crea un SPOOL para almacenar los datos que se van a operar en una cola y la CPU trabaja en él. Este proceso en sí mismo hace que Spooling sea inútil para usar en entornos en tiempo real donde necesitamos resultados en tiempo real de la CPU. Esto se debe a que el dispositivo de entrada es más lento y, por lo tanto, produce sus datos a un ritmo más lento, mientras que la CPU puede operar más rápido, por lo que pasa al siguiente proceso en la cola. Es por eso que el resultado final se produce más tarde en lugar de en tiempo real.
Diferencia entre spooling y buffering
La cola y el almacenamiento en búfer son las dos formas en que los subsistemas de E/S mejoran el rendimiento y la eficiencia de la computadora mediante el uso de un espacio de almacenamiento en la memoria principal o en el disco.

La diferencia básica entre Spooling y Buffering es que Spooling superpone la E/S de un trabajo con la ejecución de otro trabajo. En comparación, el almacenamiento en búfer superpone las E/S de un trabajo con la ejecución del mismo trabajo. A continuación se muestran algunas diferencias más entre spooling y buffering, como por ejemplo:
prepárate para el simulacro de prueba
| Términos | En cola | Almacenamiento en búfer |
|---|---|---|
| Definición | Spooling, acrónimo de Operación periférica simultánea en línea (SPOOL), coloca los datos en un área de trabajo temporal para que otro programa o recurso pueda acceder a ellos y procesarlos. | El almacenamiento en búfer es un acto de almacenar datos temporalmente en el búfer. Ayuda a hacer coincidir la velocidad del flujo de datos entre el remitente y el receptor. |
| Requisito de recursos | El spooling requiere menos gestión de recursos, ya que diferentes recursos gestionan el proceso para trabajos específicos. | El almacenamiento en búfer requiere más gestión de recursos, ya que el mismo recurso gestiona el proceso del mismo trabajo dividido. |
| Implementación interna | El spooling superpone la entrada y salida de un trabajo con el cálculo de otro trabajo. | El almacenamiento en búfer superpone la entrada y salida de un trabajo con el cálculo del mismo trabajo. |
| Eficiente | El spooling es más eficiente que el buffering. | El almacenamiento en búfer es menos eficiente que el spooling. |
| Procesador | El spooling también puede procesar datos en sitios remotos. La cola de impresión solo tiene que notificar cuando se completa un proceso en el sitio remoto para poner en cola el siguiente proceso en el dispositivo del lado remoto. | El almacenamiento en búfer no admite el procesamiento remoto. |
| Tamaño en memoria | Considera el disco como un enorme spool o buffer. | El búfer es un área limitada en la memoria principal. |