A Red neuronal convolucional (CNN) es un tipo de arquitectura de red neuronal de aprendizaje profundo comúnmente utilizada en visión por computadora. La visión por computadora es un campo de la Inteligencia Artificial que permite a una computadora comprender e interpretar la imagen o los datos visuales.
Cuando se trata de aprendizaje automático, Redes neuronales artificiales funcionar muy bien. Las redes neuronales se utilizan en varios conjuntos de datos como imágenes, audio y texto. Se utilizan diferentes tipos de redes neuronales para diferentes propósitos, por ejemplo para predecir la secuencia de palabras que usamos. Redes neuronales recurrentes más precisamente un LSTM De manera similar, para la clasificación de imágenes utilizamos redes neuronales convolucionales. En este blog, vamos a construir un componente básico para CNN.
En una red neuronal normal existen tres tipos de capas:
carácter a cadena java
- Capas de entrada: Es la capa en la que le damos entrada a nuestro modelo. La cantidad de neuronas en esta capa es igual a la cantidad total de características en nuestros datos (la cantidad de píxeles en el caso de una imagen).
- Capa oculta: La entrada de la capa de entrada luego se introduce en la capa oculta. Puede haber muchas capas ocultas dependiendo de nuestro modelo y tamaño de datos. Cada capa oculta puede tener diferentes números de neuronas que generalmente son mayores que el número de características. La salida de cada capa se calcula mediante la multiplicación matricial de la salida de la capa anterior con los pesos que se pueden aprender de esa capa y luego mediante la suma de sesgos que se pueden aprender seguido de una función de activación que hace que la red no sea lineal.
- Capa de salida: Luego, la salida de la capa oculta se introduce en una función logística como sigmoide o softmax que convierte la salida de cada clase en la puntuación de probabilidad de cada clase.
Los datos se introducen en el modelo y la salida de cada capa se obtiene del paso anterior que se llama avance , luego calculamos el error usando una función de error, algunas funciones de error comunes son la entropía cruzada, el error de pérdida cuadrática, etc. La función de error mide qué tan bien se está desempeñando la red. Después de eso, propagamos hacia atrás en el modelo calculando las derivadas. Este paso se llama La red neuronal convolucional (CNN) es la versión extendida de redes neuronales artificiales (RNA) que se utiliza predominantemente para extraer la característica del conjunto de datos matriciales en forma de cuadrícula. Por ejemplo, conjuntos de datos visuales como imágenes o vídeos donde los patrones de datos desempeñan un papel importante.
Arquitectura CNN
La red neuronal convolucional consta de varias capas, como la capa de entrada, la capa convolucional, la capa de agrupación y capas completamente conectadas.

Arquitectura CNN sencilla
La capa convolucional aplica filtros a la imagen de entrada para extraer características, la capa de agrupación reduce la muestra de la imagen para reducir el cálculo y la capa completamente conectada hace la predicción final. La red aprende los filtros óptimos mediante retropropagación y descenso de gradiente.
Cómo funcionan las capas convolucionales
Las Redes Neuronales Convolucionales o covnets son redes neuronales que comparten sus parámetros. Imagina que tienes una imagen. Se puede representar como un cuboide que tiene su largo, ancho (dimensión de la imagen) y alto (es decir, el canal, ya que las imágenes generalmente tienen canales rojo, verde y azul).
Ahora imagine tomar una pequeña parte de esta imagen y ejecutar una pequeña red neuronal, llamada filtro o núcleo, con, digamos, K salidas y representarlas verticalmente. Ahora deslice esa red neuronal por toda la imagen y, como resultado, obtendremos otra imagen con diferentes anchos, altos y profundidades. En lugar de solo canales R, G y B, ahora tenemos más canales pero menos ancho y alto. Esta operación se llama Circunvolución . Si el tamaño del parche es el mismo que el de la imagen, será una red neuronal normal. Debido a este pequeño parche, tenemos menos pesos.
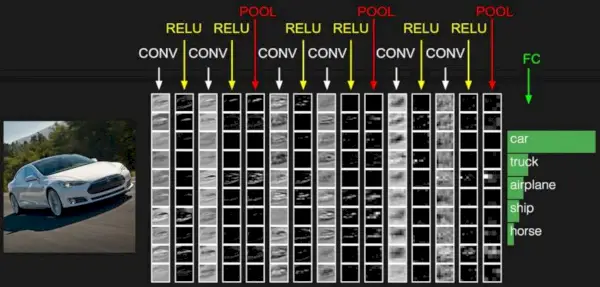
Fuente de la imagen: Aprendizaje profundo Udacity
Ahora hablemos un poco de matemáticas involucradas en todo el proceso de convolución.
- Las capas de convolución constan de un conjunto de filtros (o núcleos) que se pueden aprender que tienen anchos y alturas pequeños y la misma profundidad que el volumen de entrada (3 si la capa de entrada es una entrada de imagen).
- Por ejemplo, si tenemos que ejecutar convolución en una imagen con dimensiones 34x34x3. El tamaño posible de los filtros puede ser axax3, donde 'a' puede ser 3, 5 o 7, pero más pequeño en comparación con la dimensión de la imagen.
- Durante el paso hacia adelante, deslizamos cada filtro por todo el volumen de entrada paso a paso, donde se llama cada paso paso (que puede tener un valor de 2, 3 o incluso 4 para imágenes de alta dimensión) y calcular el producto escalar entre los pesos del núcleo y el parche del volumen de entrada.
- A medida que deslizamos nuestros filtros, obtendremos una salida 2-D para cada filtro y, como resultado, los apilaremos, obtendremos un volumen de salida con una profundidad igual a la cantidad de filtros. La red aprenderá todos los filtros.
Capas utilizadas para construir ConvNets
Una arquitectura completa de redes neuronales convolucionales también se conoce como covnets. Un covnets es una secuencia de capas, y cada capa transforma un volumen en otro mediante una función diferenciable.
Tipos de capas: conjuntos de datos
Tomemos un ejemplo ejecutando covnets en una imagen de dimensión 32 x 32 x 3.
- Capas de entrada: Es la capa en la que le damos entrada a nuestro modelo. En CNN, generalmente, la entrada será una imagen o una secuencia de imágenes. Esta capa contiene la entrada sin procesar de la imagen con ancho 32, alto 32 y profundidad 3.
- Capas convolucionales: Esta es la capa que se utiliza para extraer la característica del conjunto de datos de entrada. Aplica un conjunto de filtros que se pueden aprender conocidos como núcleos a las imágenes de entrada. Los filtros/núcleos son matrices más pequeñas, generalmente de forma 2×2, 3×3 o 5×5. se desliza sobre los datos de la imagen de entrada y calcula el producto escalar entre el peso del núcleo y el parche de imagen de entrada correspondiente. La salida de esta capa se conoce como mapas de características. Supongamos que usamos un total de 12 filtros para esta capa, obtendremos un volumen de salida de dimensión 32 x 32 x 12.
- Capa de activación: Al agregar una función de activación a la salida de la capa anterior, las capas de activación agregan no linealidad a la red. aplicará una función de activación por elementos a la salida de la capa convolucional. Algunas funciones de activación comunes son reanudar : máx(0,x), Sospechoso , RELU con fugas , etc. El volumen permanece sin cambios, por lo tanto, el volumen de salida tendrá unas dimensiones de 32 x 32 x 12.
- Capa de agrupación: Esta capa se inserta periódicamente en los covnets y su función principal es reducir el tamaño del volumen, lo que hace que el cálculo sea rápido, reduce la memoria y también evita el sobreajuste. Dos tipos comunes de capas de agrupación son agrupación máxima y agrupación promedio . Si utilizamos una piscina max con filtros 2 x 2 y zancada 2, el volumen resultante será de dimensiones 16x16x12.
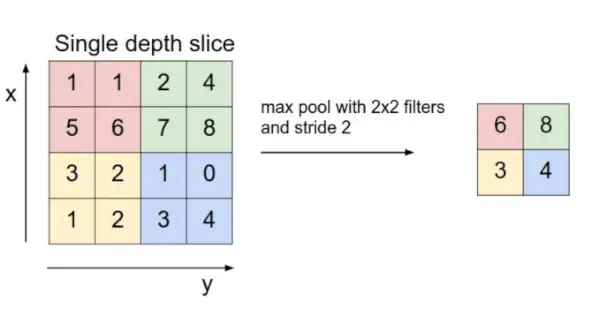
Fuente de la imagen: cs231n.stanford.edu
- Aplastamiento: Los mapas de características resultantes se aplanan en un vector unidimensional después de las capas de convolución y agrupación para que puedan pasarse a una capa completamente vinculada para categorización o regresión.
- Capas completamente conectadas: Toma la entrada de la capa anterior y calcula la tarea de clasificación o regresión final.
Fuente de la imagen: cs231n.stanford.edu
milivecriclet
- Capa de salida: Luego, la salida de las capas completamente conectadas se introduce en una función logística para tareas de clasificación como sigmoide o softmax, que convierte la salida de cada clase en la puntuación de probabilidad de cada clase.
Ejemplo:
Consideremos una imagen y apliquemos la operación de capa de convolución, capa de activación y capa de agrupación para extraer la característica interna.
Imagen de entrada:
Imagen de entrada
Paso:
- importar las bibliotecas necesarias
- establecer el parámetro
- definir el núcleo
- Cargue la imagen y trácela.
- Reformatear la imagen
- Aplique la operación de capa de convolución y trace la imagen de salida.
- Aplique la operación de capa de activación y trace la imagen de salida.
- Aplique la operación de capa de agrupación y trace la imagen de salida.
Python3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
>
Producción :

Imagen original en escala de grises
Producción
objeto en programación java
Ventajas de las redes neuronales convolucionales (CNN):
- Bueno para detectar patrones y características en imágenes, videos y señales de audio.
- Robusto ante la traslación, la rotación y la invariancia de escala.
- Capacitación de un extremo a otro, sin necesidad de extracción manual de funciones.
- Puede manejar grandes cantidades de datos y lograr una alta precisión.
Desventajas de las redes neuronales convolucionales (CNN):
- Es computacionalmente costoso de entrenar y requiere mucha memoria.
- Puede ser propenso a sobreajustarse si no se utilizan suficientes datos o una regularización adecuada.
- Requiere grandes cantidades de datos etiquetados.
- La interpretabilidad es limitada, es difícil entender lo que la red ha aprendido.
Preguntas frecuentes (FAQ)
1: ¿Qué es una red neuronal convolucional (CNN)?
Una red neuronal convolucional (CNN) es un tipo de red neuronal de aprendizaje profundo adecuada para el análisis de imágenes y videos. Las CNN utilizan una serie de capas de convolución y agrupación para extraer características de imágenes y videos, y luego usan estas características para clasificar o detectar objetos o escenas.
2: ¿Cómo funcionan las CNN?
Las CNN funcionan aplicando una serie de capas de convolución y agrupación a una imagen o video de entrada. Las capas de convolución extraen características de la entrada deslizando un pequeño filtro, o núcleo, sobre la imagen o el video y calculando el producto escalar entre el filtro y la entrada. Luego, las capas de agrupación reducen la resolución de la salida de las capas convolucionales para reducir la dimensionalidad de los datos y hacerlos más eficientes computacionalmente.
3: ¿Cuáles son algunas funciones de activación comunes utilizadas en las CNN?
Algunas funciones de activación comunes utilizadas en las CNN incluyen:
- Unidad lineal rectificada (ReLU): ReLU es una función de activación no saturada que es computacionalmente eficiente y fácil de entrenar.
- Unidad lineal rectificada con fugas (Leaky ReLU): Leaky ReLU es una variante de ReLU que permite que una pequeña cantidad de gradiente negativo fluya a través de la red. Esto puede ayudar a evitar que la red muera durante el entrenamiento.
- Unidad lineal rectificada paramétrica (PReLU): PReLU es una generalización de Leaky ReLU que permite aprender la pendiente del gradiente negativo.
4: ¿Cuál es el propósito de utilizar múltiples capas convolucionales en una CNN?
El uso de múltiples capas de convolución en una CNN permite a la red aprender características cada vez más complejas a partir de la imagen o el video de entrada. Las primeras capas de convolución aprenden características simples, como bordes y esquinas. Las capas de convolución más profundas aprenden características más complejas, como formas y objetos.
5: ¿Cuáles son algunas técnicas de regularización comunes utilizadas en las CNN?
Se utilizan técnicas de regularización para evitar que las CNN sobreajusten los datos de entrenamiento. Algunas técnicas de regularización comunes utilizadas en las CNN incluyen:
- Abandono: el abandono elimina aleatoriamente neuronas de la red durante el entrenamiento. Esto obliga a la red a aprender características más sólidas que no dependen de una sola neurona.
- Regularización L1: la regularización L1 regulariza el valor absoluto de los pesos en la red. Esto puede ayudar a reducir la cantidad de pesos y hacer que la red sea más eficiente.
- Regularización L2: la regularización L2 regulariza el cuadrado de los pesos en la red. Esto también puede ayudar a reducir la cantidad de pesos y hacer que la red sea más eficiente.
6: ¿Cuál es la diferencia entre una capa de convolución y una capa de agrupación?
Una capa de convolución extrae características de una imagen o video de entrada, mientras que una capa de agrupación reduce la resolución de la salida de las capas de convolución. Las capas de convolución utilizan una serie de filtros para extraer características, mientras que las capas de agrupación utilizan una variedad de técnicas para reducir la muestra de los datos, como la agrupación máxima y la agrupación promedio.