La siguiente arquitectura explica el flujo de envío de consultas a Hive.
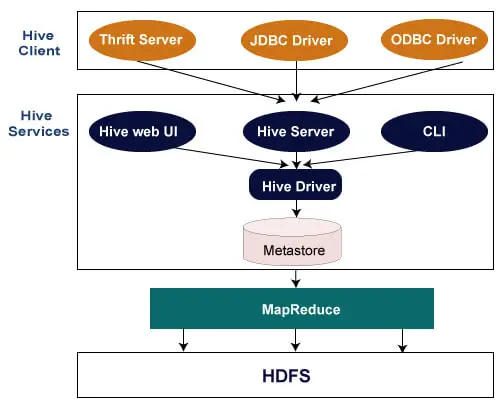
Cliente de colmena
Hive permite escribir aplicaciones en varios lenguajes, incluidos Java, Python y C++. Admite diferentes tipos de clientes como: -
- Thrift Server: es una plataforma de proveedor de servicios en varios idiomas que atiende solicitudes de todos aquellos lenguajes de programación que admiten Thrift.
- Controlador JDBC: se utiliza para establecer una conexión entre las aplicaciones Hive y Java. El controlador JDBC está presente en la clase org.apache.hadoop.hive.jdbc.HiveDriver.
- Controlador ODBC: permite que las aplicaciones que admiten el protocolo ODBC se conecten a Hive.
Servicios de colmena
Los siguientes son los servicios proporcionados por Hive: -
- CLI de Hive: la CLI de Hive (interfaz de línea de comandos) es un shell donde podemos ejecutar consultas y comandos de Hive.
- Interfaz de usuario web de Hive: la interfaz de usuario web de Hive es solo una alternativa a la CLI de Hive. Proporciona una GUI basada en web para ejecutar consultas y comandos de Hive.
- Hive MetaStore: es un repositorio central que almacena toda la información estructural de varias tablas y particiones en el almacén. También incluye metadatos de columna y su tipo de información, los serializadores y deserializadores que se utilizan para leer y escribir datos y los archivos HDFS correspondientes donde se almacenan los datos.
- Servidor Hive: se lo conoce como servidor Apache Thrift. Acepta la solicitud de diferentes clientes y se la proporciona a Hive Driver.
- Controlador Hive: recibe consultas de diferentes fuentes, como la interfaz de usuario web, CLI, Thrift y el controlador JDBC/ODBC. Transfiere las consultas al compilador.
- Compilador de Hive: el propósito del compilador es analizar la consulta y realizar un análisis semántico de los diferentes bloques y expresiones de consulta. Convierte declaraciones de HiveQL en trabajos de MapReduce.
- Hive Execution Engine: el optimizador genera el plan lógico en forma de DAG de tareas de reducción de mapas y tareas HDFS. Al final, el motor de ejecución ejecuta las tareas entrantes en el orden de sus dependencias.